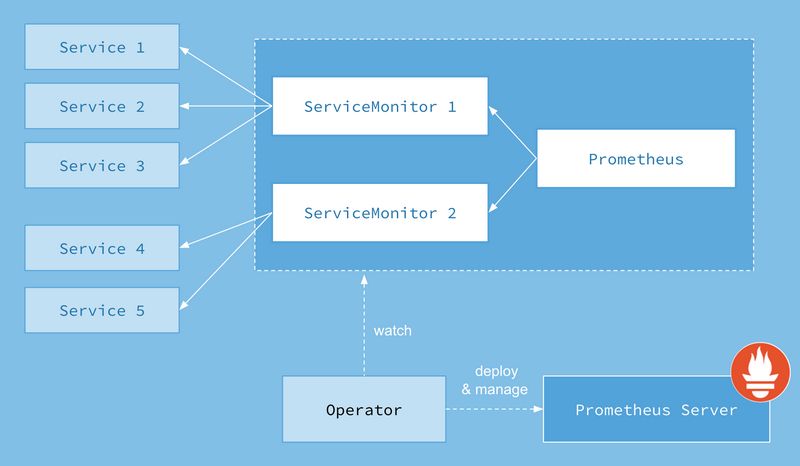
简介 前面我们学习了用自定义的方式来对 Kubernetes 集群进行监控,但是还是有一些缺陷,比如 Prometheus、AlertManager 这些组件服务本身的高可用。当然我们也完全可以用自定义的方式来实现这些需求,Promethues 在代码上就已经对 Kubernetes 有了原生的支持,可以通过服务发现的形式来自动监控集群,因此我们可以使用另外一种更加高级的方式来部署 Prometheus:Kube-Prometheus(Operator) 框架。
Operator是由CoreOS公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器。它被用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator 是基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识:比如创建一个数据库的Operator,则必须对创建的数据库的各种运维方式非常了解,创建Operator的关键是CRD(自定义资源)的设计。
[scode type=”red”] 注:CRD是对 Kubernetes API 的扩展,Kubernetes 中的每个资源都是一个 API 对象的集合,例如我们在 YAML文件里定义的那些spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operator是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
资源: 对象的状态定义;控制器: 观测、分析和行动,以调节资源的分布。
在最新的版本中,Kubernetes的 Prometheus-Operator 部署内容已经从 Prometheus-Operator 的 Github工程中拆分出独立工程Kube-Prometheus。Kube-Prometheus 即是通过 Operator 方式部署的Kubernetes集群监控,所以我们直接容器化部署 Kube-Prometheus 即可。
Kube-Prometheus项目地址:https://github.com/coreos/kube-prometheus
因为我们前面Kubernetes集群的安装版本为v1.18.3,为了考虑兼容性、这里我们安装 Kube-Prometheus-Release-0.5 版本。当然大家也可以去 Kube-Prometheus 的文档中查看兼容性列表,如下:
[scode type=”red”]注:关于 Kube-Prometheus 更多的介绍内容、大家可以移步官方文档详细查看。
部署kube-Prometheus 环境介绍
名称
版本
系统版本
Centos 7.6
集群部署方式
Kubeadm
K8s集群版本
v1.18.3
kube-Prometheus版本
v0.5.0
[scode type=”green”]Github项目地址:https://github.com/coreos/kube-prometheus
1.下载0.5.0的kube-prometheus二进制包解压并归类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 [root@k8s-master k8s-yaml]$ wget https://github.com/coreos/kube-prometheus/archive/v0.5.0.tar.gz [root@k8s-master k8s-yaml]$ tar xzvf v0.5.0.tar.gz [root@k8s-master k8s-yaml]$ cd kube-prometheus-0.5.0/manifests/ [root@k8s-master k8s-yaml]$ mkdir -p operator node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter add-service mv *-serviceMonitor* serviceMonitor/mv grafana-* grafana/mv kube-state-metrics-* kube-state-metrics/mv alertmanager-* alertmanager/mv node-exporter-* node-exporter/mv prometheus-adapter* adapter/mv prometheus-* prometheus/mv setup/prometheus-operator-* ./operator/mv setup/0namespace-namespace.yaml ./[root@k8s-master manifests] . ├── 0namespace-namespace.yaml ├── adapter │ ├── prometheus-adapter-apiService.yaml │ ├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml │ ├── prometheus-adapter-clusterRoleBindingDelegator.yaml │ ├── prometheus-adapter-clusterRoleBinding.yaml │ ├── prometheus-adapter-clusterRoleServerResources.yaml │ ├── prometheus-adapter-clusterRole.yaml │ ├── prometheus-adapter-configMap.yaml │ ├── prometheus-adapter-deployment.yaml │ ├── prometheus-adapter-roleBindingAuthReader.yaml │ ├── prometheus-adapter-serviceAccount.yaml │ └── prometheus-adapter-service.yaml ├── add-service ├── alertmanager │ ├── alertmanager-alertmanager.yaml │ ├── alertmanager-secret.yaml │ ├── alertmanager-serviceAccount.yaml │ └── alertmanager-service.yaml ├── grafana │ ├── grafana-dashboardDatasources.yaml │ ├── grafana-dashboardDefinitions.yaml │ ├── grafana-dashboardSources.yaml │ ├── grafana-deployment.yaml │ ├── grafana-serviceAccount.yaml │ └── grafana-service.yaml ├── kube-state-metrics │ ├── kube-state-metrics-clusterRoleBinding.yaml │ ├── kube-state-metrics-clusterRole.yaml │ ├── kube-state-metrics-deployment.yaml │ ├── kube-state-metrics-serviceAccount.yaml │ └── kube-state-metrics-service.yaml ├── node-exporter │ ├── node-exporter-clusterRoleBinding.yaml │ ├── node-exporter-clusterRole.yaml │ ├── node-exporter-daemonset.yaml │ ├── node-exporter-serviceAccount.yaml │ └── node-exporter-service.yaml ├── operator │ ├── prometheus-operator-0alertmanagerCustomResourceDefinition.yaml │ ├── prometheus-operator-0podmonitorCustomResourceDefinition.yaml │ ├── prometheus-operator-0prometheusCustomResourceDefinition.yaml │ ├── prometheus-operator-0prometheusruleCustomResourceDefinition.yaml │ ├── prometheus-operator-0servicemonitorCustomResourceDefinition.yaml │ ├── prometheus-operator-0thanosrulerCustomResourceDefinition.yaml │ ├── prometheus-operator-clusterRoleBinding.yaml │ ├── prometheus-operator-clusterRole.yaml │ ├── prometheus-operator-deployment.yaml │ ├── prometheus-operator-serviceAccount.yaml │ └── prometheus-operator-service.yaml ├── prometheus │ ├── prometheus-clusterRoleBinding.yaml │ ├── prometheus-clusterRole.yaml │ ├── prometheus-prometheus.yaml │ ├── prometheus-roleBindingConfig.yaml │ ├── prometheus-roleBindingSpecificNamespaces.yaml │ ├── prometheus-roleConfig.yaml │ ├── prometheus-roleSpecificNamespaces.yaml │ ├── prometheus-rules.yaml │ ├── prometheus-serviceAccount.yaml │ └── prometheus-service.yaml ├── serviceMonitor │ ├── alertmanager-serviceMonitor.yaml │ ├── grafana-serviceMonitor.yaml │ ├── kube-state-metrics-serviceMonitor.yaml │ ├── node-exporter-serviceMonitor.yaml │ ├── prometheus-operator-serviceMonitor.yaml │ ├── prometheus-serviceMonitorApiserver.yaml │ ├── prometheus-serviceMonitorCoreDNS.yaml │ ├── prometheus-serviceMonitorKubeControllerManager.yaml │ ├── prometheus-serviceMonitorKubelet.yaml │ ├── prometheus-serviceMonitorKubeScheduler.yaml │ └── prometheus-serviceMonitor.yaml └── setup
2.修改Prometheus、grafana、altermanager的svc类型为NodePort 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 [root@k8s-master manifests ]$ vim prometheus/prometheus-service.yaml apiVersion: v1 kind: Service metadata: labels: prometheus: k8s name: prometheus-k8s namespace: monitoring spec: ports: - name: web port: 9090 targetPort: web selector: app: prometheus prometheus: k8s sessionAffinity: ClientIP type: NodePort [root@k8s-master manifests ]$ vim grafana/grafana-service.yaml apiVersion: v1 kind: Service metadata: labels: app: grafana name: grafana namespace: monitoring spec: ports: - name: http port: 3000 targetPort: http selector: app: grafana type: NodePort [root@k8s-master manifests ] apiVersion: v1 kind: Service metadata: labels: alertmanager: main name: alertmanager-main namespace: monitoring spec: ports: - name: web port: 9093 targetPort: web selector: alertmanager: main app: alertmanager sessionAffinity: ClientIP type: NodePort
3.应用各服务的资源清单 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 [root@k8s-master manifests]$ kubectl apply -f . namespace/monitoring created [root@k8s-master manifests]$ kubectl apply -f operator/ customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created clusterrole.rbac.authorization.k8s.io/prometheus-operator created clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created service/prometheus-operator created serviceaccount/prometheus-operator created [root@k8s-master manifests]$ kubectl apply -f adapter/ apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io configured clusterrole.rbac.authorization.k8s.io/prometheus-adapter created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created configmap/adapter-config created deployment.apps/prometheus-adapter created rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created service/prometheus-adapter created serviceaccount/prometheus-adapter created [root@k8s-master manifests]$ kubectl apply -f alertmanager/ alertmanager.monitoring.coreos.com/main created secret/alertmanager-main created service/alertmanager-main created serviceaccount/alertmanager-main created [root@k8s-master manifests]$ kubectl apply -f node-exporter/ clusterrole.rbac.authorization.k8s.io/node-exporter created clusterrolebinding.rbac.authorization.k8s.io/node-exporter created daemonset.apps/node-exporter created service/node-exporter created serviceaccount/node-exporter created [root@k8s-master manifests]$ kubectl apply -f kube-state-metrics/ clusterrole.rbac.authorization.k8s.io/kube-state-metrics created clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created service/kube-state-metrics created serviceaccount/kube-state-metrics created [root@k8s-master manifests]$ kubectl apply -f grafana/ secret/grafana-datasources created configmap/grafana-dashboard-apiserver created configmap/grafana-dashboard-cluster-total created configmap/grafana-dashboard-controller-manager created configmap/grafana-dashboard-k8s-resources-cluster created configmap/grafana-dashboard-k8s-resources-namespace created configmap/grafana-dashboard-k8s-resources-node created configmap/grafana-dashboard-k8s-resources-pod created configmap/grafana-dashboard-k8s-resources-workload created configmap/grafana-dashboard-k8s-resources-workloads-namespace created configmap/grafana-dashboard-kubelet created configmap/grafana-dashboard-namespace-by-pod created configmap/grafana-dashboard-namespace-by-workload created configmap/grafana-dashboard-node-cluster-rsrc-use created configmap/grafana-dashboard-node-rsrc-use created configmap/grafana-dashboard-nodes created configmap/grafana-dashboard-persistentvolumesusage created configmap/grafana-dashboard-pod-total created configmap/grafana-dashboard-prometheus-remote-write created configmap/grafana-dashboard-prometheus created configmap/grafana-dashboard-proxy created configmap/grafana-dashboard-scheduler created configmap/grafana-dashboard-statefulset created configmap/grafana-dashboard-workload-total created configmap/grafana-dashboards created deployment.apps/grafana created service/grafana created serviceaccount/grafana created [root@k8s-master manifests]$ kubectl apply -f prometheus/ clusterrole.rbac.authorization.k8s.io/prometheus-k8s created clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created prometheus.monitoring.coreos.com/k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s-config created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created prometheusrule.monitoring.coreos.com/prometheus-k8s-rules created service/prometheus-k8s created serviceaccount/prometheus-k8s created [root@k8s-master manifests]$ kubectl apply -f serviceMonitor/ servicemonitor.monitoring.coreos.com/alertmanager created servicemonitor.monitoring.coreos.com/grafana created servicemonitor.monitoring.coreos.com/kube-state-metrics created servicemonitor.monitoring.coreos.com/node-exporter created servicemonitor.monitoring.coreos.com/prometheus-operator created servicemonitor.monitoring.coreos.com/prometheus created servicemonitor.monitoring.coreos.com/kube-apiserver created servicemonitor.monitoring.coreos.com/coredns created servicemonitor.monitoring.coreos.com/kube-controller-manager created servicemonitor.monitoring.coreos.com/kube-scheduler created servicemonitor.monitoring.coreos.com/kubelet created
4.查看资源状态 [scode type=”yellow”]这里镜像默认是国外的镜像源,没有科学上网导致镜像拉取失败pod无法启动的问题,可以找个能科学上网的服务器,将yaml中的image手动pull下来打包,然后导入到节点本地。[/scode]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 [root@k8s-master manifests] NAME READY STATUS RESTARTS AGE pod/alertmanager-main-0 2/2 Running 0 4m46s pod/alertmanager-main-1 2/2 Running 0 4m46s pod/alertmanager-main-2 2/2 Running 0 4m46s pod/grafana-5c55845445-hq4gq 1/1 Running 0 4m37s pod/kube-state-metrics-957fd6c75-66xc8 3/3 Running 0 4m43s pod/node-exporter-dbkx6 2/2 Running 0 4m52s pod/node-exporter-f66sn 2/2 Running 0 4m52s pod/node-exporter-lfrmz 2/2 Running 0 4m52s pod/prometheus-adapter-5949969998-9dp4z 1/1 Running 0 5m4s pod/prometheus-k8s-0 3/3 Running 1 4m30s pod/prometheus-k8s-1 3/3 Running 1 4m30s pod/prometheus-operator-574fd8ccd9-qfrr5 2/2 Running 0 5m12s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/alertmanager-main NodePort 10.98.68.37 <none> 9093:30744/TCP 4m59s service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 4m46s service/grafana NodePort 10.100.3.234 <none> 3000:32682/TCP 4m37s service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 4m44s service/node-exporter ClusterIP None <none> 9100/TCP 4m52s service/prometheus-adapter ClusterIP 10.97.247.251 <none> 443/TCP 5m5s service/prometheus-k8s NodePort 10.107.38.102 <none> 9090:32691/TCP 4m31s service/prometheus-operated ClusterIP None <none> 9090/TCP 4m31s service/prometheus-operator ClusterIP None <none> 8443/TCP 5m13s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-exporter 3 3 3 3 3 kubernetes.io/os=linux 4m52s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/grafana 1/1 1 1 4m37s deployment.apps/kube-state-metrics 1/1 1 1 4m44s deployment.apps/prometheus-adapter 1/1 1 1 5m5s deployment.apps/prometheus-operator 1/1 1 1 5m14s NAME DESIRED CURRENT READY AGE replicaset.apps/grafana-5c55845445 1 1 1 4m37s replicaset.apps/kube-state-metrics-957fd6c75 1 1 1 4m44s replicaset.apps/prometheus-adapter-5949969998 1 1 1 5m5s replicaset.apps/prometheus-operator-574fd8ccd9 1 1 1 5m14s NAME READY AGE statefulset.apps/alertmanager-main 3/3 4m46s statefulset.apps/prometheus-k8s 2/2 4m31s
5.访问Prometheus和grafana的NodePort暴露端口验证 1 2 3 4 5 6 7 8 9 10 11 12 [root@k8s-master manifests] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main NodePort 10.98.68.37 <none> 9093:30744/TCP 12m alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 12m grafana NodePort 10.100.3.234 <none> 3000:32682/TCP 12m kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 12m node-exporter ClusterIP None <none> 9100/TCP 12m prometheus-adapter ClusterIP 10.97.247.251 <none> 443/TCP 13m prometheus-k8s NodePort 10.107.38.102 <none> 9090:32691/TCP 12m prometheus-operated ClusterIP None <none> 9090/TCP 12m prometheus-operator ClusterIP None <none> 8443/TCP 13m
访问Prometheus暴露出来的svc-NodePort验证 访问Grafana暴露的svc-NodePort端口访问验证
这里导入了一个Node-export的仪表板验证node-export是否部署成功。
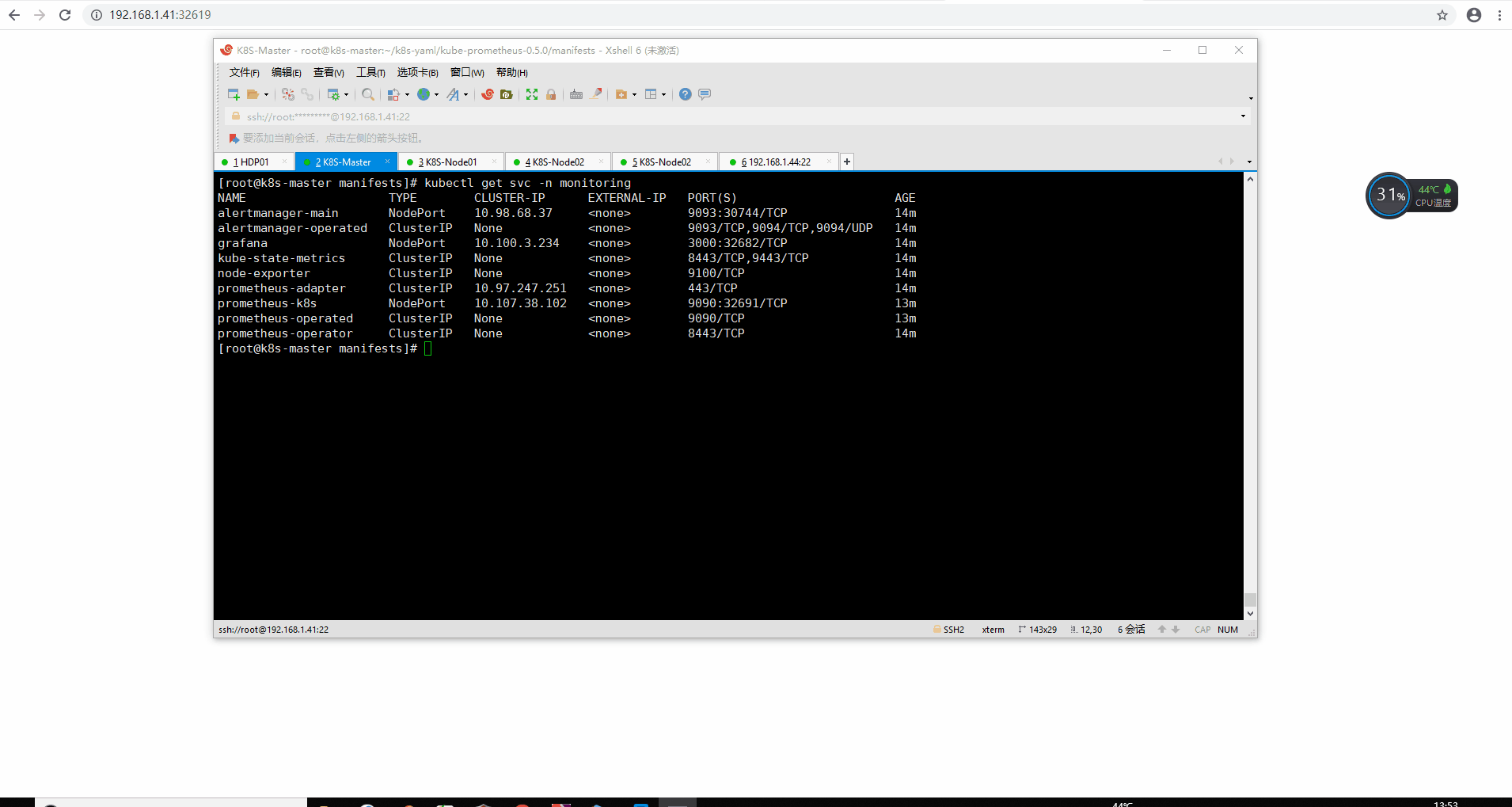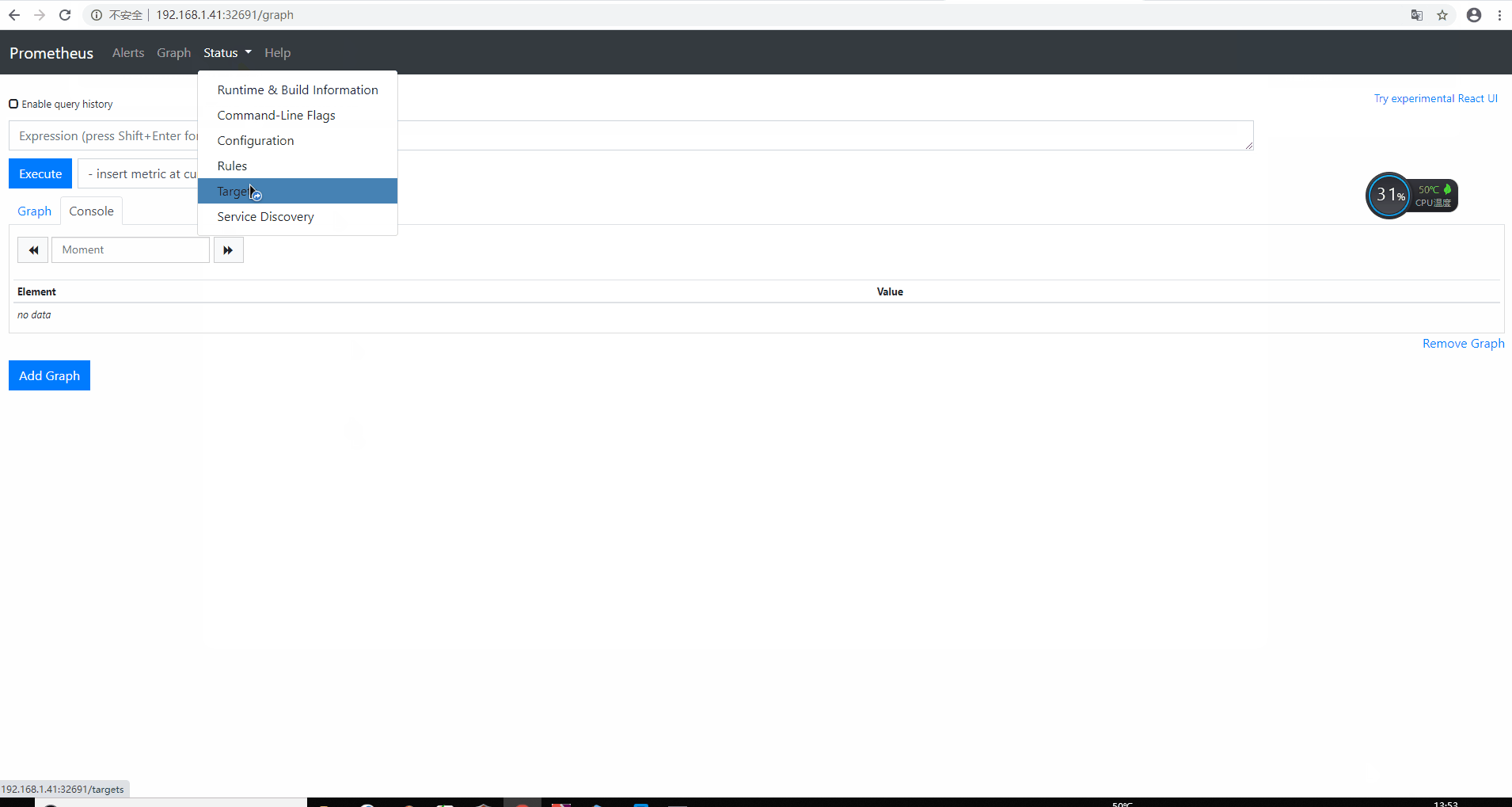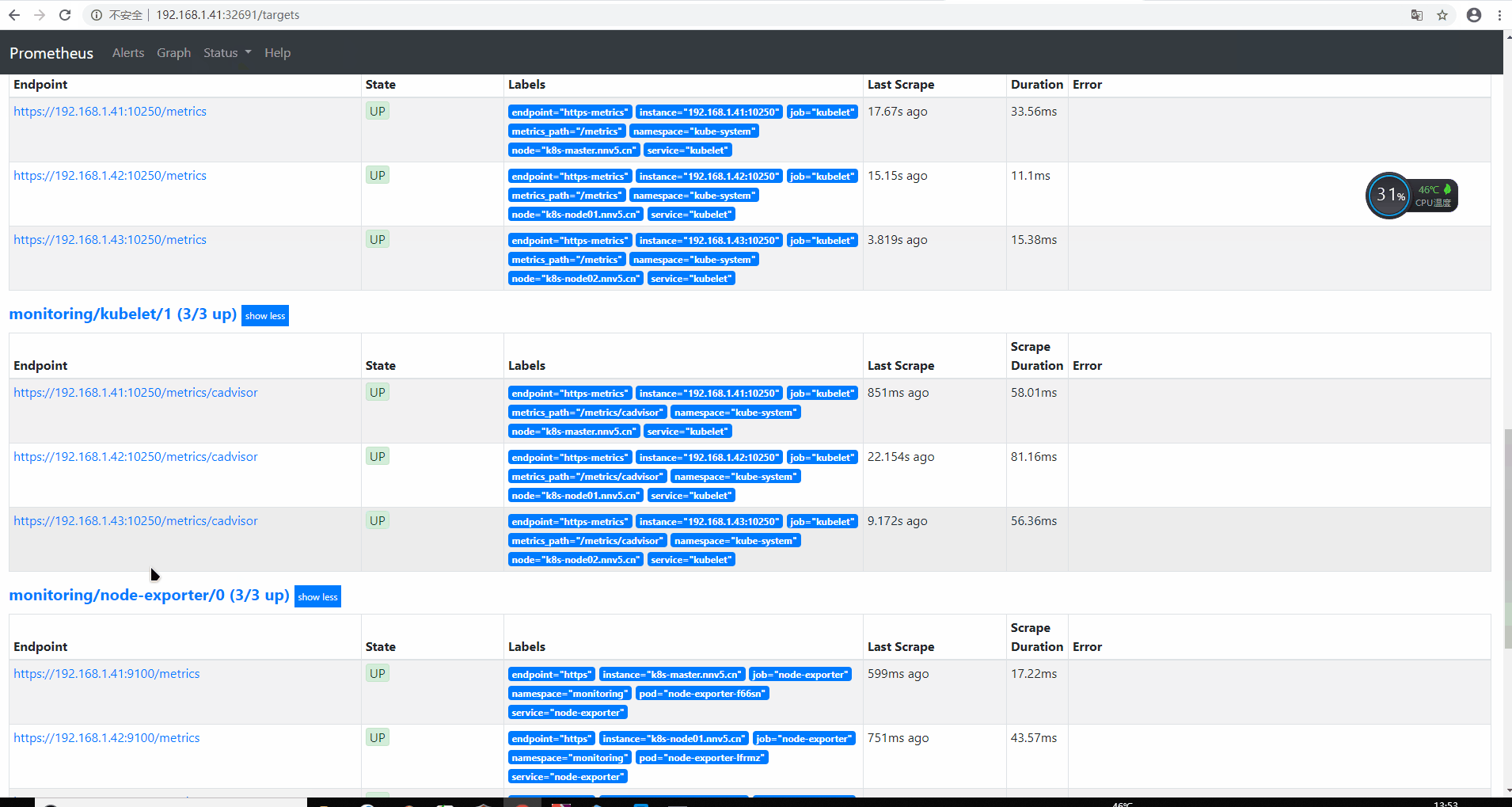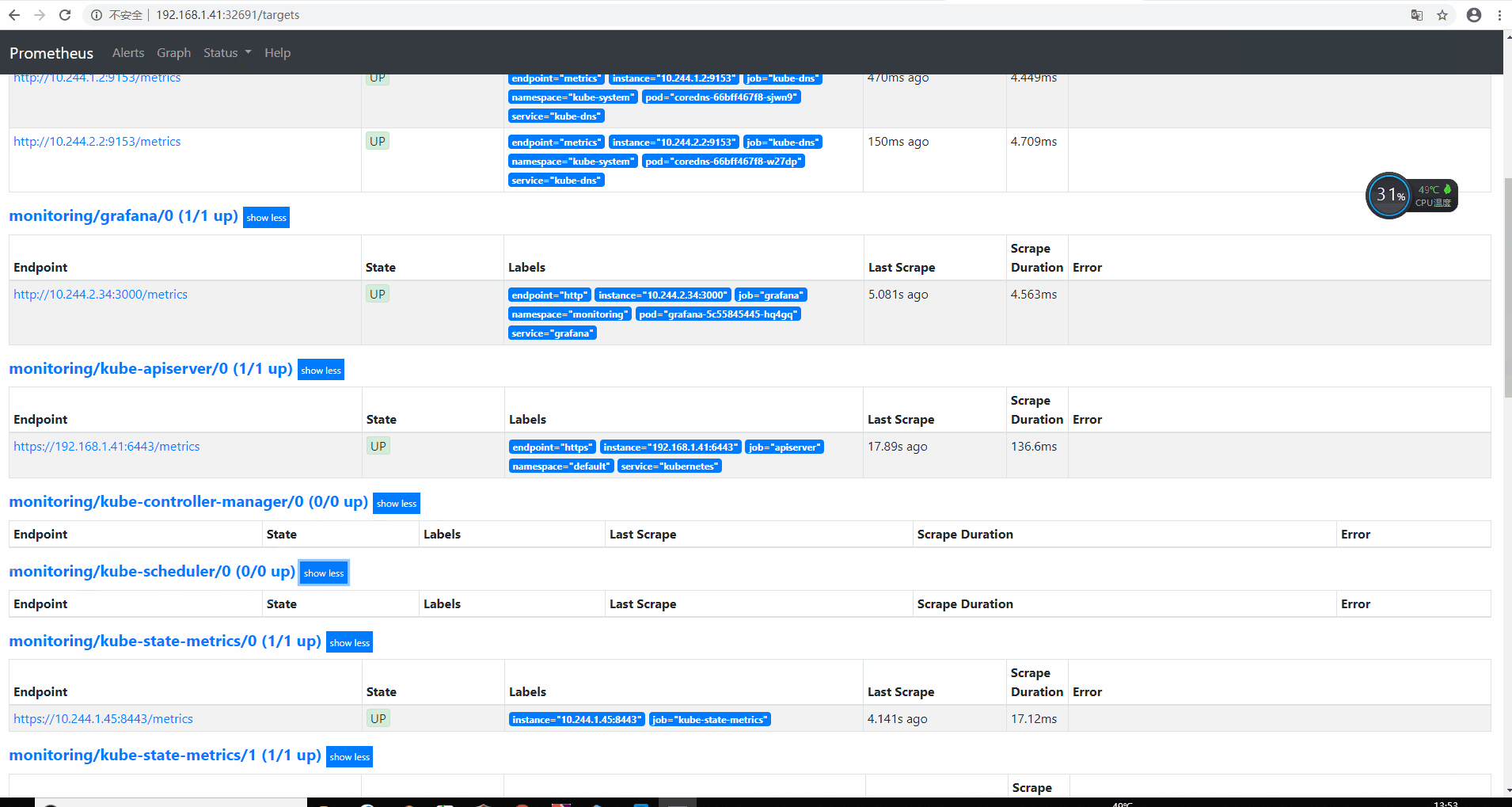
配置Prometheus监控scheduler与controller [scode type=”blue”]我们可以看到大部分的配置都是正常的,只有两个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件,这就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义(prometheus-serviceMonitorKubeScheduler.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@k8s-master manifests ]$ cat serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: monitoring spec: endpoints: - interval: 30s port: http-metrics jobLabel: k8s-app namespaceSelector: matchNames: - kube-system selector: matchLabels: k8s-app: kube-scheduler
[scode type=”blue”]上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过selector.matchLabels在 kube-system 这个命名空间下面匹配具有k8s-app=kube-scheduler这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service(prometheus-kubeSchedulerService.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@k8s-master manifests ]$ vim add-service/prometheus-kubeSchedulerService.yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: k8s-app: kube-scheduler spec: ports: - name: http-metrics port: 10251 targetPort: 10251 protocol: TCP
[scode type=”blue”]
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: ports: - name: https-metrics port: 10252 targetPort: 10252 protocol: TCP
应用前面创建的两个svc资源清单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@k8s-master manifests]$ kubectl apply -f add-service/prometheus-kubeSchedulerService.yaml service/kube-scheduler created [root@k8s-master manifests]$ kubectl apply -f add-service/prometheus-KubeControllerManagerService.yaml service/kube-controller-manager created [root@k8s-master manifests]$ kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-controller-manager ClusterIP 10.105.234.92 <none> 10252/TCP 7s kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 4d21h kube-scheduler ClusterIP 10.100.155.182 <none> 10251/TCP 12s kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 5h5m metrics-server ClusterIP 10.110.42.192 <none> 443/TCP 4d5h tiller-deploy ClusterIP 10.100.234.68 <none> 44134/TCP 3d21h
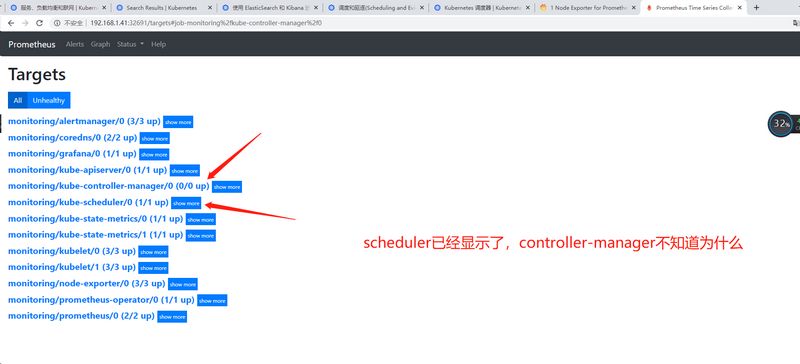
[scode type=”blue”]但是此时Prometheus面板的 targets 还是没有任何显示,我们通过 kubectl get ep -n kube-system 命令去查看一下 kube-controller-manager 和 kube-scheduler 的endpoints发现并没有任何endpoints,这里我们需要手动来添加endpoints。我们定义两个endpoints资源文件,如下:[/scode]
1 2 3 4 5 6 7 8 9 [root@k8s-master manifests]$ kubectl get ep -n kube-system NAME ENDPOINTS AGE kube-controller-manager <none> 4d21h kube-dns 10.244.1.2:53,10.244.2.2:53,10.244.1.2:9153 + 3 more... 4d21h kube-scheduler <none> 4d21h kubelet 192.168.1.41:4194,192.168.1.42:4194,192.168.1.43:4194 + 6 more... 5h7m metrics-server 10.244.2.27:443 4d5h tiller-deploy <none> 3d22h
[scode type=”red”]修改:prometheus-kubeSchedulerServiceEnpoints.yaml,修改之后ep里面能看到节点的ip地址了,但是Prometheus里面没有(后面再研究)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@k8s-master manifests] apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager annotations: prometheus.io/scrape: 'true' spec: selector: component: kube-controller-manager type : ClusterIP clusterIP: None ports: - name: http-metrics port: 10252 targetPort: 10252 protocol: TCP
修改:add-service/prometheus-KubeControllerManagerService.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-master manifests]$ vim add-service/prometheus-KubeControllerManagerService.yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: ports: - name: https-metrics port: 10252 targetPort: 10252 protocol: TCP selector: component: kube-controller-manager
[scode type=”blue”]应用上面的配置文件修改,重新查看ep的关联[/scode]
1 2 3 4 5 6 7 8 9 10 11 12 [root@k8s-master manifests]$ kubectl apply -f add-service/prometheus-kubeSchedulerService.yaml [root@k8s-master manifests]$ kubectl apply -f add-service/prometheus-KubeControllerManagerService.yaml [root@k8s-master manifests] NAME ENDPOINTS AGE kube-controller-manager 192.168.1.41:10252 4d22h kube-dns 10.244.1.2:53,10.244.2.2:53,10.244.1.2:9153 + 3 more... 4d22h kube-scheduler 192.168.1.41:10251 4d22h kubelet 192.168.1.41:4194,192.168.1.42:4194,192.168.1.43:4194 + 6 more... 5h51m metrics-server 10.244.2.27:443 4d6h
[scode type=”red”]访问Prometheus查看controller-manager和scheduler是否显示,访问grafana查看数据展示
Prometheus自定义监控etcd 1。获取etcd的证书路径 [scode type=”blue”]对于 etcd 集群一般情况下,为了安全都会开启 https 证书认证的方式,所以要想让 Prometheus 访问到 etcd 集群的监控数据,就需要提供相应的证书校验。
由于我们这里演示环境使用的是 Kubeadm 搭建的集群,我们可以使用 kubectl 工具去获取 etcd 启动的时候使用的证书路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@k8s-master ~]$ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE etcd-k8s-master.nnv5.cn 1/1 Running 0 5d16h [root@k8s-master ~]$ kubectl get pods -n kube-system etcd-k8s-master.nnv5.cn -oyaml --export ......省略 spec: containers: - command : - etcd - --advertise-client-urls=https://192.168.1.41:2379 - --cert-file=/etc/kubernetes/pki/etcd/server.crt - --client-cert-auth=true - --data-dir=/var/lib/etcd - --initial-advertise-peer-urls=https://192.168.1.41:2380 - --initial-cluster=k8s-master.nnv5.cn=https://192.168.1.41:2380 - --key-file=/etc/kubernetes/pki/etcd/server.key - --listen-client-urls=https://127.0.0.1:2379,https://192.168.1.41:2379 - --listen-metrics-urls=http://127.0.0.1:2381 - --listen-peer-urls=https://192.168.1.41:2380 - --name=k8s-master.nnv5.cn - --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt - --peer-client-cert-auth=true - --peer-key-file=/etc/kubernetes/pki/etcd/peer.key - --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt - --snapshot-count=10000 - --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt ······省略
2。创建etcd使用的secret配置到Prometheus资源中 [scode type=”blue”]我们可以看到 etcd 使用的证书都对应在节点的 /etc/kubernetes/pki/etcd 这个路径下面,所以首先我们将需要使用到的证书通过 secret 对象保存到集群中去:(在 etcd 运行的节点)
1 2 3 4 5 6 7 8 [root@k8s-master manifests]$ kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt secret "etcd-certs" created [root@k8s-master ~]$ kubectl get secrets -n monitoring NAME TYPE DATA AGE etcd-certs Opaque 3 18h
将上面创建的secret添加到Prometheus的资源对象中并验证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@k8s-master manifests]$ pwd /root/k8s-yaml/kube-prometheus-0.5.0/manifests [root@k8s-master manifests]$ vim prometheus/prometheus-prometheus.yaml nodeSelector: kubernetes.io/os: linux podMonitorNamespaceSelector: {} podMonitorSelector: {} replicas: 2 secrets: - etcd-certs [root@k8s-master manifests]$ kubectl apply -f prometheus/prometheus-prometheus.yaml /prometheus $ ls /etc/prometheus/secrets/etcd-certs/ ca.crt healthcheck-client.crt healthcheck-client.key
3。创建ServiceMonitor [scode type=”blue”]现在 Prometheus 访问 etcd 集群的证书已经准备好了,接下来创建 ServiceMonitor 对象即可(prometheus-serviceMonitorEtcd.yaml)[/scode]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@k8s-master manifests ]$ pwd /root/k8s-yaml/kube-prometheus-0.5.0/manifests [root@k8s-master manifests ]vim serviceMonitor/prometheus-serviceMonitorEtcd.yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: etcd-k8s namespace: monitoring labels: k8s-app: etcd-k8s spec: jobLabel: k8s-app endpoints: - port: port interval: 30s scheme: https tlsConfig: caFile: /etc/prometheus/secrets/etcd-certs/ca.crt certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key insecureSkipVerify: true selector: matchLabels: k8s-app: etcd namespaceSelector: matchNames: - kube-system [root@k8s-master manifests ]
[scode type=”blue”]上面我们在 monitoring 命名空间下面创建了名为 etcd-k8s 的 ServiceMonitor 对象,匹配 kube-system 这个命名空间下面的具有 k8s-app=etcd 这个 label 标签的 Service,jobLabel 表示用于检索 job 任务名称的标签,和前面不太一样的地方是 endpoints 属性的写法,配置上访问 etcd 的相关证书,endpoints 属性下面可以配置很多抓取的参数,比如 relabel、proxyUrl,tlsConfig 表示用于配置抓取监控数据端点的 tls 认证,由于证书 serverName 和 etcd 中签发的可能不匹配,所以加上了 insecureSkipVerify=true
[scode type=”green”]关于 ServiceMonitor 属性的更多用法可以查看文档:https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md 了解更多
4。创建etcd的svc [scode type=”blue”]ServiceMonitor 创建完成了,但是现在还没有关联的对应的 Service 对象,所以需要我们去手动创建一个 Service 对象(prometheus-EtcdService.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 [root@k8s-master manifests ]$ pwd /root/k8s-yaml/kube-prometheus-0.5.0/manifests [root@k8s-master manifests ]$ vim add-service/prometheus-EtcdService.yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: etcd-k8s labels: k8s-app: etcd spec: type: ClusterIP clusterIP: None ports: - name: port port: 2379 targetPort: 2379 protocol: TCP selector: component: etcd [root@k8s-master manifests ]$ kubectl apply -f add-service/prometheus-EtcdService.yaml [root@k8s-master manifests ]$ vim add-service/prometheus-EtcdService.yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: etcd-k8s labels: k8s-app: etcd spec: type: ClusterIP clusterIP: None ports: - name: port port: 2379 targetPort: 2379 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: name: etcd-k8s namespace: kube-system labels: k8s-app: etcd subsets: - addresses: - ip: 10.151 .30 .57 nodeName: etc-master ports: - name: port port: 2379 protocol: TCP
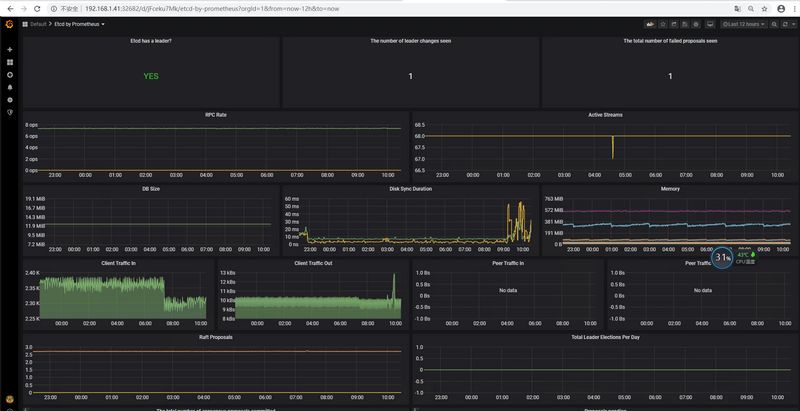
[scode type=”blue”]创建完成后,隔一会儿去 Prometheus 的 Dashboard 中查看 targets,便会有 etcd 的监控项了:
可以看到还是有一个明显的错误,和我们前面监控 kube-scheduler 的错误比较类似于,因为我们这里的 etcd 的是监听在 127.0.0.1 这个 IP 上面的,所以访问会拒绝:
1 2 [root@k8s-master manifests]$ ss -tnl | grep 2379 LISTEN 0 128 127.0.0.1:2379 *:*
同样我们只需要在 /etc/kubernetes/manifest/ 目录下面的 etcd.yaml 文件中所有127.0.0.1:2379更改成 0.0.0.0:2379 或者etcd节点IP:2379即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@k8s-master manifests ] ······省略 containers: - command: - etcd - --advertise-client-urls=https://192.168.1.41:2379 - --cert-file=/etc/kubernetes/pki/etcd/server.crt - --client-cert-auth=true - --data-dir=/var/lib/etcd - --initial-advertise-peer-urls=https://192.168.1.41:2380 - --initial-cluster=k8s-master.nnv5.cn=https://192.168.1.41:2380 - --key-file=/etc/kubernetes/pki/etcd/server.key - --listen-client-urls=https://0.0.0.0:2379,https://192.168.1.41:2379 - --listen-metrics-urls=http://127.0.0.1:2381 - --listen-peer-urls=https://192.168.1.41:2380 - --name=k8s-master.nnv5.cn - --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt - --peer-client-cert-auth=true - --peer-key-file=/etc/kubernetes/pki/etcd/peer.key - --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt - --snapshot-count=10000 - --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt image: k8s.gcr.io/etcd:3.4.3-0 imagePullPolicy: IfNotPresent ······省略 [root@k8s-master manifests ]$ kubectl apply -f /etc/kubernetes/manifests/etcd.yaml
重启 etcd,生效后,查看 etcd 这个监控任务就正常了:
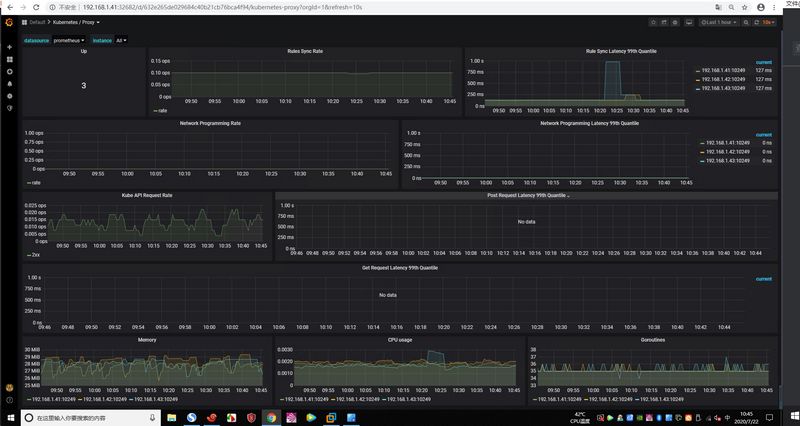
过一段时间查看grafana仪表盘
Prometheus监控kube-proxy 1。创建ServiceMonitor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@k8s-master manifests ] apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: kube-proxy name: kube-proxy namespace: monitoring spec: endpoints: - interval: 30s port: http-metrics jobLabel: k8s-app namespaceSelector: matchNames: - kube-system selector: matchLabels: k8s-app: kube-proxy [root@k8s-master manifests ]$ kubectl apply -f serviceMonitor/prometheus-serviceMonitorKubeProxy.yaml servicemonitor.monitoring.coreos.com/kube-proxy created
2。创建etcd的svc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@k8s-master manifests ] apiVersion: v1 kind: Service metadata: labels: k8s-app: kube-proxy name: kube-proxy namespace: kube-system spec: type: ClusterIP clusterIP: None ports: - name: http-metrics port: 10249 protocol: TCP targetPort: 10249 selector: k8s-app: kube-proxy [root@k8s-master manifests ]$ kubectl apply -f add-service/prometheus-KubeProxyService.yaml service/kube-proxy created [root@k8s-master manifests ]$ kubectl get svc,ep -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ...... service/kube-proxy ClusterIP None <none> 10249 /TCP 3m8s ...... NAME ENDPOINTS AGE ...... endpoints/kube-proxy 192.168 .1 .41 :10249,192.168.1.42:10249,192.168.1.43:10249 11s ......
[scode type=”red”]需要注意的是:serviceMoitor中的select标签需要和下面svc中的标签一样,svc中的selector标签需要与集群中kube-proxy的pod标签一致。
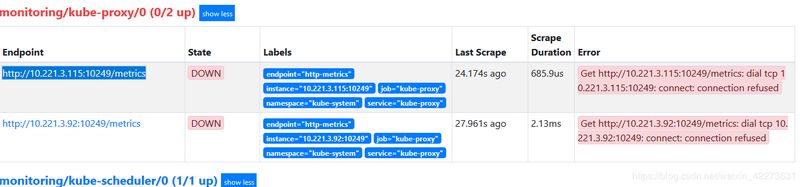
svc和serviceMonitor资源清单应用之后查看Prometheus发现有监控项但是状态为Down
默认情况下,kubeadm安装集群后该服务监听端口只提供给127.0.0.1,需修改为0.0.0.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-node01 tmp ] LISTEN 0 128 127.0 .0 .1 :10249 :::* [root@k8s-master manifests ] apiVersion: v1 data: config.conf: |- apiVersion: kubeproxy.config.k8s.io/v1alpha1 metricsBindAddress: "0.0.0.0" ······省略 [root@k8s-master manifests ]
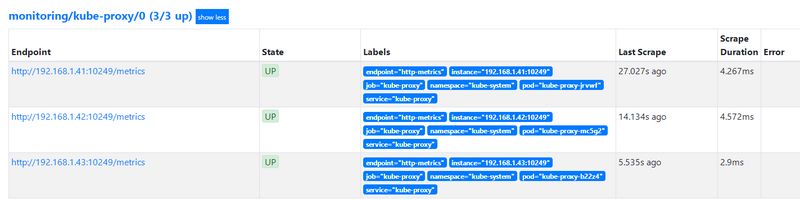
等kube-proxy的pod重建成功之后再查看Prometheus状态变为UP
kube-Prometheus数据持久化 [scode type=”blue”]前面我们需改完Prometheus的相关配置后,重启了 Prometheus 的 Pod,如果我们仔细观察的话会发现我们之前采集的数据已经没有了,这是因为我们通过 Prometheus 这个 CRD 创建的 Prometheus 并没有做数据的持久化,我们可以直接查看生成的 Prometheus Pod 的挂载情况就清楚了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@k8s-master manifests ] ······省略 volumes: - name: config secret: defaultMode: 420 secretName: prometheus-k8s - name: tls-assets secret: defaultMode: 420 secretName: prometheus-k8s-tls-assets - emptyDir: {} name: config-out - configMap: defaultMode: 420 name: prometheus-k8s-rulefiles-0 name: prometheus-k8s-rulefiles-0 - name: secret-etcd-certs secret: defaultMode: 420 secretName: etcd-certs - emptyDir: {} name: prometheus-k8s-db - name: prometheus-k8s-token-nt5mv secret: defaultMode: 420 secretName: prometheus-k8s-token-nt5mv ······省略
[scode type=”blue”]从上图我们可以看到 Prometheus 的数据目录 /prometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,所以如果 Pod 挂掉了,数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,对应线上的监控数据肯定需要做数据的持久化的,同样的 prometheus 这个 CRD 资源也为我们提供了数据持久化的配置方法,由于我们的 Prometheus 最终是通过 Statefulset 控制器进行部署的,所以我们这里需要通过 storageclass 来做数据持久化,首先创建一个 StorageClass 对象(prometheus-storageclass.yaml):
安装nfs服务器
1 2 3 4 5 6 7 8 [root@nfs ~] [root@nfs ~] [root@nfs ~] /data/volumes/nfs 192.168.1.0/24(rw,no_root_squash) [root@nfs ~] [root@nfs ~] Export list for 192.168.1.21: /data/volumes/nfs 192.168.1.0/24
创建nfs-client-provisioner的RBC文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 ]$ vim nfs-client-provisioner-RBAC.yaml apiVersion: v1 kind: ServiceAccount metadata: name: nfs-client-provisioner namespace: default --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-client-provisioner-runner rules: - apiGroups: ["" ] resources: ["persistentvolumes" ] verbs: ["get" , "list" , "watch" , "create" , "delete" ] - apiGroups: ["" ] resources: ["persistentvolumeclaims" ] verbs: ["get" , "list" , "watch" , "update" ] - apiGroups: ["storage.k8s.io" ] resources: ["storageclasses" ] verbs: ["get" , "list" , "watch" ] - apiGroups: ["" ] resources: ["events" ] verbs: ["create" , "update" , "patch" ] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: default roleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner namespace: default rules: - apiGroups: ["" ] resources: ["endpoints" ] verbs: ["get" , "list" , "watch" , "create" , "update" , "patch" ] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: default roleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io ]$ kubectl apply -f nfs-client-provisioner-RBAC.yaml serviceaccount/nfs-client-provisioner created clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
创建deployment部署资源清单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 [root@k8s-master NFS-Client-Provisioner ]$ vim nfs-client-provisioner-Deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner namespace: default spec: replicas: 1 selector: matchLabels: app: nfs-client-provisioner strategy: type: Recreate template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: quay.io/external_storage/nfs-client-provisioner:latest volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: test.nnv5.cn/nfs - name: NFS_SERVER value: 192.168 .1 .21 - name: NFS_PATH value: /data/volumes/nfs volumes: - name: nfs-client-root nfs: server: 192.168 .1 .21 path: /data/volumes/nfs [root@k8s-master NFS-Client-Provisioner ]$ kubectl apply -f nfs-client-provisioner-Deploy.yaml deployment.apps/nfs-client-provisioner created [root@k8s-master NFS-Client-Provisioner ]$ kubectl get pods NAME READY STATUS RESTARTS AGE nfs-client-provisioner-788c5bc7cb-kcflx 1 /1 Running 0 4m56s
[scode type=”blue”]创建一个Prometheus持久化时候的存储类,调用我们上面部署的nfs存储,注意provisioner: test.nnv5.cn/nfs 对象中的nfs-client-provisioner 指定的provisioner:值需要与上面部署的nfs存储驱动中的PROVISIONER_NAME中的值要一致。
1 2 3 4 5 6 7 8 9 [root@k8s-master manifests]$ vim prometheus/prometheus-storageclass.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: prometheus-data-db provisioner: test.nnv5.cn/nfs [root@k8s-master manifests]$ kubectl apply -f prometheus/prometheus-storageclass.yaml storageclass.storage.k8s.io/prometheus-data-db created
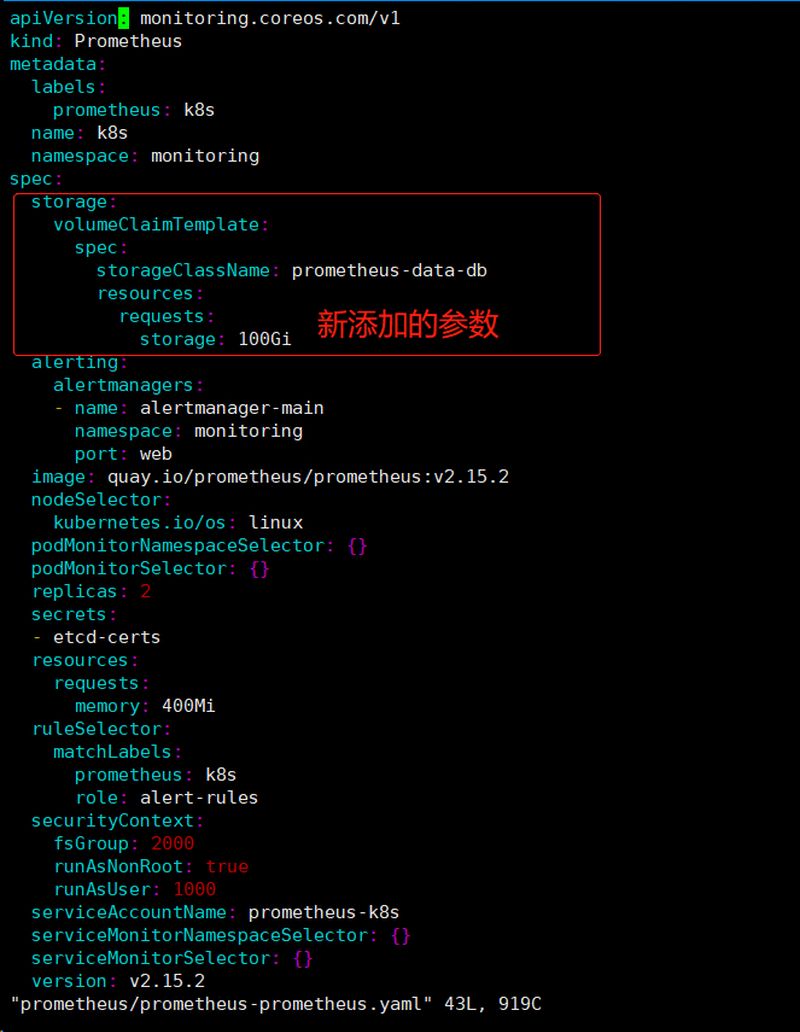
修改Prometheus的资源清单添加nfs的存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@k8s-master manifests]$ vim prometheus/prometheus-prometheus.yaml ······省略 storage: volumeClaimTemplate: spec: storageClassName: prometheus-data-db resources: requests: storage: 100Gi ······省略 [root@k8s-master manifests]$ kubectl apply -f prometheus/prometheus-prometheus.yaml prometheus.monitoring.coreos.com/k8s configured
[scode type=”red”]注意这里的 storageClassName 名字为上面我们创建的 StorageClass 对象名称,然后更新 prometheus 这个 CRD 资源(应用资源清单之后k8s节点需要安装nfs-utils,否则pod调度到对应节点后需要使用nfs挂载,从而导致pod启动失败)。更新完成后会自动生成两个 PVC 和 PV 资源对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@k8s-master manifests]$ kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE prometheus-k8s-0 3/3 Running 1 4m23s prometheus-k8s-1 3/3 Running 1 4m23s [root@k8s-master manifests]$ kubectl get pv,pvc -n monitoring NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE persistentvolume/pvc-52b3acdf-4748-40ae-a8fb-cc3c73f42955 100Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-0 prometheus-data-db 6m5s persistentvolume/pvc-7bc112bc-192f-4fde-87d5-e5061dd1cb99 100Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-1 prometheus-data-db 6m5s NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/prometheus-k8s-db-prometheus-k8s-0 Bound pvc-52b3acdf-4748-40ae-a8fb-cc3c73f42955 100Gi RWO prometheus-data-db 6m5s persistentvolumeclaim/prometheus-k8s-db-prometheus-k8s-1 Bound pvc-7bc112bc-192f-4fde-87d5-e5061dd1cb99 100Gi RWO prometheus-data-db 6m5s
[scode type=”blue”]现在我们再去看 Prometheus Pod 的数据目录就可以看到是关联到一个 PVC 对象上了。现在即使我们的 Pod 挂掉了,数据也不会丢失了。删除对应pod后新建的pod还是关联之前使用的pvc,数据实际存储到远程nfs服务器的/data/volumes/nfs目录下.
1 2 3 4 5 6 [root@nfs ~]$ cd /data/volumes/nfs/ [root@nfs nfs]$ ll total 0 drwxrwxrwx 3 root root 27 Jul 22 13:45 monitoring-prometheus-k8s-db-prometheus-k8s-0-pvc-52b3acdf-4748-40ae-a8fb-cc3c73f42955 drwxrwxrwx 3 root root 27 Jul 22 13:49 monitoring-prometheus-k8s-db-prometheus-k8s-1-pvc-7bc112bc-192f-4fde-87d5-e5061dd1cb99
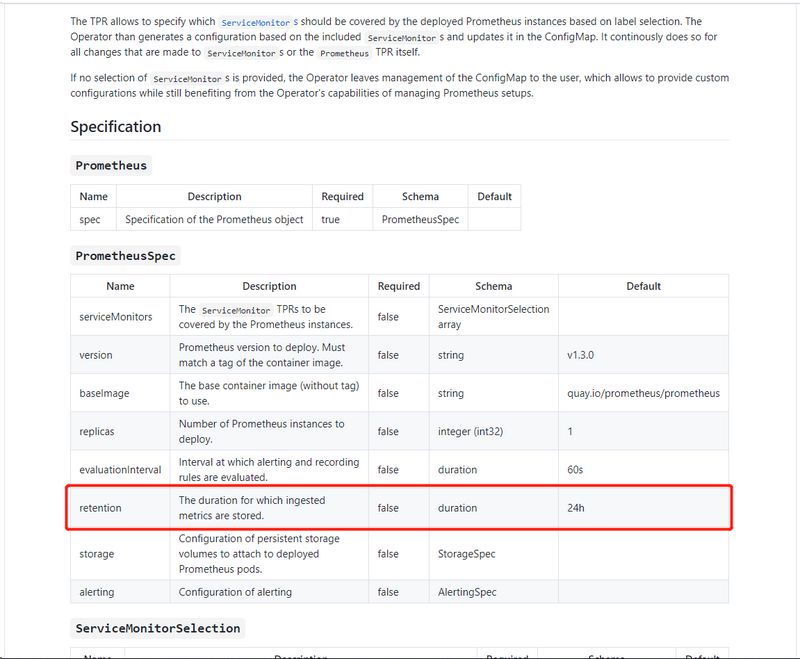
Kube-Prometheus数据持久时间 [scode type=”blue”]前面说了prometheus operator数据持久化的问题,但是还有一个问题很多人都忽略了,那就是prometheus operator数据保留天数,根据官方文档的说明,默认prometheus operator数据存储的时间为24小时,这个时候无论你prometheus operator如何进行持久化,都没有作用,因为数据只保留了1天,那么你是无法看到更多天数的数据。
官方文档可以配置的说明:https://github.com/coreos/prometheus-operator/blob/0e6ed120261f101e6f0dc9581de025f136508ada/Documentation/prometheus.md
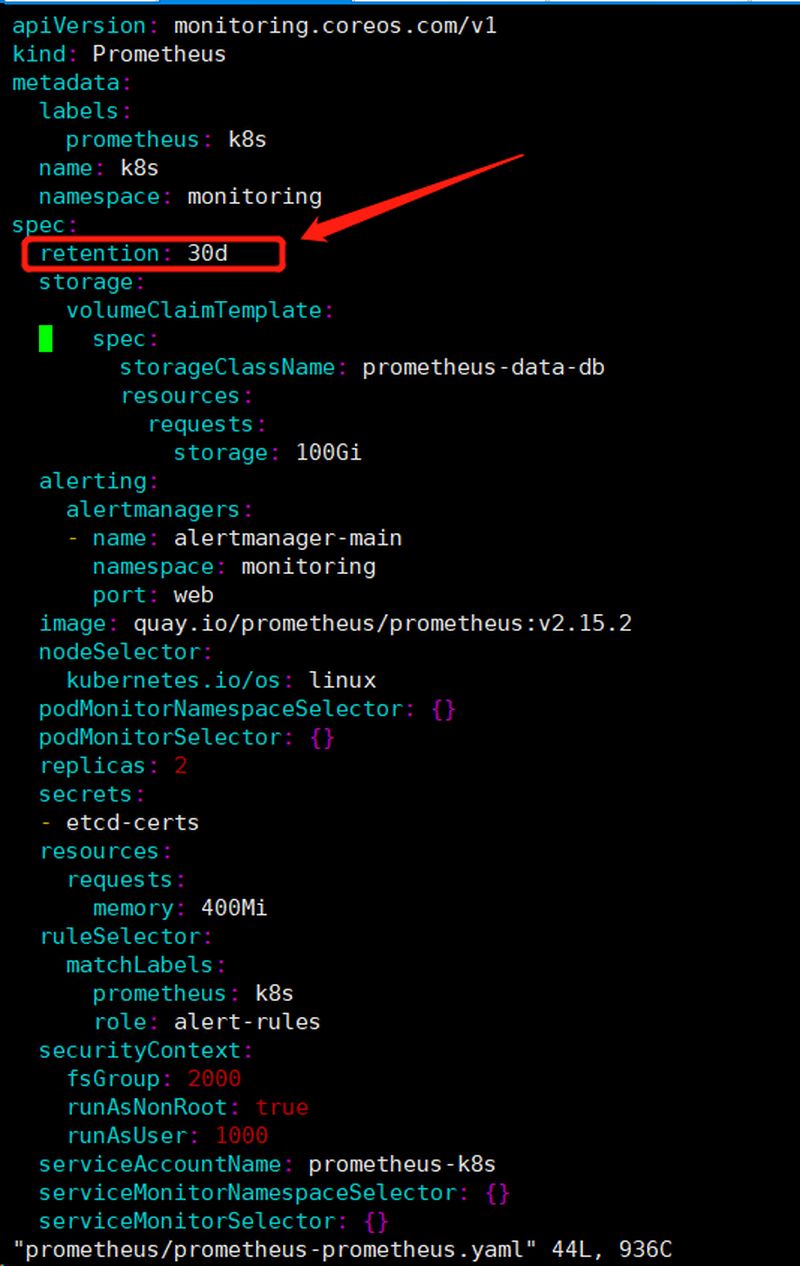
[scode type=”yello”]实际上我们修改 Kube-Prometheus 数据持久化时间是通过 retention 参数进行修改,上面也提示了在prometheus.spec下填写。这里我们直接修改 prometheus-prometheus.yaml 文件,并添加下面的参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-master manifests]$ vim prometheus/prometheus-prometheus.yaml apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: labels: prometheus: k8s name: k8s namespace: monitoring spec: retention: 30d ······省略 [root@k8s-master manifests]$ kubectl apply -f prometheus/prometheus-prometheus.yaml prometheus.monitoring.coreos.com/k8s configured
[scode type=”red”]注:如果已经安装了可以直接修改 prometheus-prometheus.yaml 然后通过kubectl apply -f 刷新即可,修改完成以后记得检查Pod运行状态是否正常。
接下来可以访问grafana或者prometheus ui进行检查 (我这里修改完毕后等待2天,检查数据是否正常)。
修改前
修改后
Grafana数据持久化 [scode type=”blue”]前面我们介绍了关于prometheus的数据持久化、但是没有介绍如何针对Grafana做数据持久化;如果Grafana不做数据持久化、那么Pod重启以后,Grafana里面配置的Dashboard、账号密码等信息将会丢失;所以Grafana做数据持久化也是很有必要的。
原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同;出现问题时,容器重启,在Grafana里面设置的数据就全部消失了。
1 2 3 4 5 6 7 8 9 10 ······省略 volumeMounts: - mountPath: /var/lib/grafana name: grafana-storage readOnly: false ... volumes: - emptyDir: {} name: grafana-storage ······省略
从上图我们可以看出Grafana将dashboard、插件这些数据保存在/var/lib/grafana这个目录下面。做持久化的话,就需要创建一个pvc,然后deploy挂载pvc到pod中,这样当pod重建之后,之前的数据也不会丢失了。
创建一个grafana数据持久化使用的存储类,调用我们上面部署的nfs存储,注意provisioner: test.nnv5.cn/nfs 对象中的nfs-client-provisioner 指定的provisioner:值需要与上面部署的nfs存储驱动中的PROVISIONER_NAME中的值要一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-master manifests ] /root/k8s-yaml/kube-prometheus-0.5.0/manifests [root@k8s-master manifests ] apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: grafana-db-storage provisioner: test.nnv5.cn/nfs [root@k8s-master manifests ] [root@k8s-master manifests ] NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE grafana-db-storage test.nnv5.cn/nfs Delete Immediate false 38m prometheus-data-db test.nnv5.cn/nfs Delete Immediate false 92m
创建一个grafana使用的pvc,通过前面创建的grafana-storageclass动态供给pv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@k8s-master manifests] /root/k8s-yaml/kube-prometheus-0.5.0/manifests [root@k8s-master manifests] apiVersion: v1 kind: PersistentVolumeClaim metadata: name: grafana-db-storage namespace: monitoring spec: accessModes: - ReadWriteOnce resources: requests: storage: 100Gi storageClassName: grafana-db-storage [root@k8s-master manifests] [root@k8s-master manifests] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE grafana-db-storage Bound pvc-b19eefab-26f5-4163-b74b-2471be56c05b 100Gi RWO grafana-db-storage 1m
修改grafana的Deployment资源清单文件,将volumes.grafana-storage存储类型改为pvc存储,调用我们刚刚创建的pvc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@k8s-master manifests] ······省略 volumes: - emptyDir: {} name: grafana-storage ······省略 ······省略 volumes: - name: grafana-storage persistentVolumeClaim: claimName: grafana-db-storage ······省略 [root@k8s-master manifests]$ kubectl apply -f grafana/grafana-deployment.yaml
重新应用grafana-deployment资源清单之后会重新启动grafana的pod,之后再删除pod重新启动数据就不会丢失了,持久化的数据是保存在nfs服务器的共享目录下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@k8s-master manifests] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES grafana-684fff9679-284lm 1/1 Running 0 32m 10.244.2.42 k8s-node02.nnv5.cn <none> <none> [root@nfs nfs] /data/volumes/nfs [root@nfs nfs] total 0 drwxrwxrwx 4 root root 50 Jul 22 14:47 archived-monitoring-grafana-db-storage-pvc-1de3ee58-2458-4389-b77f-22d694a4e0ca drwxrwxrwx 4 root root 50 Jul 22 15:25 monitoring-grafana-db-storage-pvc-b19eefab-26f5-4163-b74b-2471be56c05b drwxrwxrwx 3 root root 27 Jul 22 13:45 monitoring-prometheus-k8s-db-prometheus-k8s-0-pvc-52b3acdf-4748-40ae-a8fb-cc3c73f42955 drwxrwxrwx 3 root root 27 Jul 22 13:49 monitoring-prometheus-k8s-db-prometheus-k8s-1-pvc-7bc112bc-192f-4fde-87d5-e5061dd1cb99 [root@nfs nfs] [root@nfs monitoring-grafana-db-storage-pvc-b19eefab-26f5-4163-b74b-2471be56c05b] 1.6M grafana.db 0 plugins 0 png
[scode type=”blue”]本文转至:https://blog.z0ukun.com/?p=2605[/scode]