Kubeadm-v1.18.3部署EFK集群 前面我们介绍了 Kubernetes集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。 Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。 Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
我们先来配置启动一个可扩展的 Elasticsearch 集群,然后在 Kubernetes 集群中创建一个 Kibana 应用,最后通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。
系统环境介绍
名称
版本
系统版本
Centos 7.6
集群部署方式
Kubeadm
K8s集群版本
v1.18.3
ElasticSearch版本
v7.4.2
Kibana版本
v7.4.2
fluentd版本
v3.0.2
[scode type=”green”]Github项目地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch
一、创建 Elasticsearch 集群 Kubernetes1.18.0版本安装目录中包含的有EFK集群安装的所有文件、这里我们直接去对应目录下面创建相应资源即可。我们使用3个 Elasticsearch Pod 来避免高可用下多节点集群中出现的“脑裂”问题,当一个或多个节点无法与其他节点通信时会产生“脑裂”,可能会出现几个主节点。我们应该设置参数discover.zen.minimum_master_nodes=N/2+1,其中N是 Elasticsearch 集群中符合主节点的节点数,比如这里3个节点,意味着N应该设置为2。这样,如果一个节点暂时与集群断开连接,则另外两个节点可以选择一个新的主节点,并且集群可以在最后一个节点尝试重新加入时继续运行,在扩展 Elasticsearch 集群时,一定要记住这个参数。
[scode type=”red”]注:关于 Elasticsearch 集群脑裂问题,大家可以查看文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain
1.1 下载fluentd-elasticsearch部署文件到本地 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-master k8s-yaml] [root@k8s-master fluentd-elasticsearch] es-service.yaml es-statefulset.yaml fluentd-es-configmap.yaml fluentd-es-ds.yaml kibana-deployment.yaml kibana-service.yaml EOF [root@k8s-master fluentd-elasticsearch] [root@k8s-master fluentd-elasticsearch] es-service.yaml fluentd-es-configmap.yaml kibana-deployment.yaml list.txt elasticsearch.tar.gz es-statefulset.yaml fluentd-es-ds.yaml kibana-service.yaml
1.2 修改es-service资源清单并应用 我们先去创建一个名为 elasticsearch-logging 的无头服务,前面从官方源码里面已经下载了资源清单文件,我们只需要修改一下及可以了,默认部署在了kube-system名称空间,我这里保持默认。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@k8s-master fluentd-elasticsearch]$ vim es-service.yaml apiVersion: v1 kind: Service metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "false" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Elasticsearch" spec: ports: - port: 9200 protocol: TCP targetPort: db selector: k8s-app: elasticsearch-logging [root@k8s-master fluentd-elasticsearch] [root@k8s-master fluentd-elasticsearch] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE elasticsearch-logging ClusterIP 10.101.86.17 <none> 9200/TCP 10s
1.3 修改ES-StateFulSet资源清单并应用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 [root@k8s-master fluentd-elasticsearch] apiVersion: v1 kind: ServiceAccount metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: elasticsearch-logging labels: k8s-app: elasticsearch-logging addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "services" - "namespaces" - "endpoints" verbs: - "get" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: kube-system name: elasticsearch-logging labels: k8s-app: elasticsearch-logging addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: elasticsearch-logging namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: elasticsearch-logging apiGroup: "" --- apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging version: v7.4.2 addonmanager.kubernetes.io/mode: Reconcile spec: serviceName: elasticsearch-logging replicas: 3 selector: matchLabels: k8s-app: elasticsearch-logging version: v7.4.2 template: metadata: labels: k8s-app: elasticsearch-logging version: v7.4.2 spec: serviceAccountName: elasticsearch-logging containers: - image: quay.io/fluentd_elasticsearch/elasticsearch:v7.4.2 name: elasticsearch-logging imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: db protocol: TCP - containerPort: 9300 name: transport protocol: TCP volumeMounts: - name: elasticsearch-logging mountPath: /data env : - name: "NAMESPACE" valueFrom: fieldRef: fieldPath: metadata.namespace initContainers: - image: alpine:3.6 command : ["/sbin/sysctl" , "-w" , "vm.max_map_count=262144" ] name: elasticsearch-logging-init securityContext: privileged: true volumeClaimTemplates: - metadata: name: elasticsearch-logging annotations: volume.beta.kubernetes.io/storage-class: elasticsearch-logging spec: accessModes: - ReadWriteOnce storageClassName: elasticsearch-logging resources: requests: storage: 10Gi
我这里使用了存储类,使用nfs作为存储驱动,后面定义存储类实现pv和pvc的动态供给
文件最上面定义了 elasticsearch-logging 的ServiceAccount服务账号,ClusterRole集群角色和ClusterRoleBinding集群角色绑定。
下面文件中定义了一个名为 elasticsearch-logging 的 StatefulSet 对象,然后定义 serviceName=elasticsearch-logging 和前面创建的 Service 相关联。这可以确保使用以下 DNS 地址访问 StatefulSet 中的每一个 Pod:elasticsearch-logging-[0,1,2].elasticsearch.kube-system.svc.cluster.local,其中[0,1,2]对应于已分配的 Pod 序号。 然后指定3个副本,matchLabels 设置为 k8s-app: elasticsearch-logging,所以 Pod 的模板部分.spec.template.metadata.lables也必须包含 k8s-app: elasticsearch-logging 标签。
上面 StatuefulSet 中的Pod使用的是 quay.io/fluentd_elasticsearch/elasticsearch:v7.4.2镜像,暴露了9200和9300两个端口,文件最下面定义了一个主应用程序运行之前的Init容器,这个容器执行完成后才会启动主应用程序。默认使用的是临时emptyDir存储,我将emptyDir修改为了volumeClaimTemplates以存储类的方式使用nfs存储类来为pv和pvc的动态供给,volumeMounts挂载我们定义的持久化存储名称。
前面volumeClaimTemplates调用了elasticsearch-logging这个存储类,我们下面去定义这个存储类。(我这里使用nfs存储驱动定义,由于nfs驱动我已经提前安装好了,这里只定义存储类就可以使用,如果没部署nfs存储驱动需要先部署nfs-client-provisioner存储驱动)
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@k8s-master fluentd-elasticsearch] apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: elasticsearch-logging provisioner: test.nnv5.cn/nfs [root@k8s-master fluentd-elasticsearch] [root@k8s-master fluentd-elasticsearch] NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE elasticsearch-logging test.nnv5.cn/nfs Delete Immediate false 1m
存储类创建好之后我们就可以应用我们的ststefulset资源清单访问ES集群测试了。
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@k8s-master fluentd-elasticsearch] [root@k8s-master fluentd-elasticsearch] NAME READY STATUS RESTARTS AGE elasticsearch-logging-0 1/1 Running 0 1m elasticsearch-logging-1 1/1 Running 0 1m elasticsearch-logging-2 1/1 Running 0 1m [root@k8s-master fluentd-elasticsearch] elasticsearch-logging ClusterIP 10.101.86.17 <none> 9200/TCP 18h [root@k8s-master fluentd-elasticsearch]
看到上面的信息就表明前面名为 elasticsearch-logging 的 Elasticsearch 集群成功创建了3个节点:elasticsearch-logging-0,elasticsearch-logging-1,和elasticsearch-logging-2,当前主节点是 elasticsearch-logging-0。
我们现在去看看 pvc和pv 的状态,我们可以看到当前已经自动创建了 pvc和pv 并自动绑定成功,我们去NFS共享目录下面也可以看到相关文件内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@k8s-master fluentd-elasticsearch] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE elasticsearch-logging-elasticsearch-logging-0 Bound pvc-322604c1-56c4-459f-87e9-c6ab3c100c2f 10Gi RWO elasticsearch-logging 2m elasticsearch-logging-elasticsearch-logging-1 Bound pvc-784cd476-0e88-4bdf-9069-314c3788da9c 10Gi RWO elasticsearch-logging 2m elasticsearch-logging-elasticsearch-logging-2 Bound pvc-551e7e03-0459-4344-83f9-d5d6768eda2a 10Gi RWO elasticsearch-logging 2m [root@k8s-master fluentd-elasticsearch] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-322604c1-56c4-459f-87e9-c6ab3c100c2f 10Gi RWO Delete Bound kube-system/elasticsearch-logging-elasticsearch-logging-0 elasticsearch-logging 22h pvc-551e7e03-0459-4344-83f9-d5d6768eda2a 10Gi RWO Delete Bound kube-system/elasticsearch-logging-elasticsearch-logging-2 elasticsearch-logging 19h pvc-784cd476-0e88-4bdf-9069-314c3788da9c 10Gi RWO Delete Bound kube-system/elasticsearch-logging-elasticsearch-logging-1 elasticsearch-logging 19h [root@nfs nfs] /data/volumes/nfs [root@nfs nfs] drwxrwxrwx 4 hive hdfs 29 Jul 23 14:50 kube-system-elasticsearch-logging-elasticsearch-logging-0-pvc-322604c1-56c4-459f-87e9-c6ab3c100c2f drwxrwxrwx 3 hive hdfs 19 Jul 23 14:50 kube-system-elasticsearch-logging-elasticsearch-logging-1-pvc-784cd476-0e88-4bdf-9069-314c3788da9c drwxrwxrwx 3 hive hdfs 19 Jul 23 14:50 kube-system-elasticsearch-logging-elasticsearch-logging-2-pvc-551e7e03-0459-4344-83f9-d5d6768eda2a
二、部署Kibana服务 Elasticsearch 集群启动成功后,接下来我们可以来部署 Kibana 服务,Kibana 的资源对象有两个:Service和Deployment,这两个文件在我们从官方下载的部署清单里面已经有了,我们可以修改资源清单部署直接就可以使用。
2.1 修改service资源配置 这里的 service 我们部署为NodePort的方式,后面直接通过节点的ip+暴露的端口直接就能访问到,如果有部署ingress的直接创建一个ingress使用域名方式访问会更好,我这里使用NodePort。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@k8s-node01 tmp] -rw-r--r-- 1 root root 1468 Jul 23 18:32 kibana-deployment.yaml -rw-r--r-- 1 root root 354 Jul 23 20:55 kibana-service.yaml [root@k8s-node01 tmp] apiVersion: v1 kind: Service metadata: name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Kibana" spec: ports: - port: 5601 protocol: TCP targetPort: ui selector: k8s-app: kibana-logging type : NodePort [root@k8s-node01 tmp] service/kibana-logging created [root@k8s-node01 tmp] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana-logging NodePort 10.102.188.62 <none> 5601:31621/TCP 5s
2.2 修改deploy资源清单 Kibana Pod 中配置都比较简单,唯一需要注意的是我们使用 ELASTICSEARCH_HOSTS 这个环境变量来设置 Elasticsearch 集群的端点和端口,直接使用 Kubernetes DNS 即可,此端点对应服务名称为 elasticsearch-logging,由于是一个 headless service,所以该域将解析为3个 Elasticsearch Pod 的 IP 地址列表。配置完成后,直接应用创建资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 [root@k8s-node01 tmp] apiVersion: apps/v1 kind: Deployment metadata: name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging addonmanager.kubernetes.io/mode: Reconcile spec: replicas: 1 selector: matchLabels: k8s-app: kibana-logging template: metadata: labels: k8s-app: kibana-logging annotations: seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: containers: - name: kibana-logging image: docker.elastic.co/kibana/kibana-oss:7.4.2 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m requests: cpu: 100m env : - name: ELASTICSEARCH_HOSTS value: http://elasticsearch-logging.kube-system.svc.cluster.local:9200 ports: - containerPort: 5601 name: ui protocol: TCP [root@k8s-node01 tmp] [root@k8s-node01 tmp] kibana-logging-59dc58cb7b-gk5vx 1/1 Running 0 1m [root@k8s-node01 tmp] kibana-logging NodePort 10.102.188.62 <none> 5601:31621/TCP 12m
如果 Pod 已经是 Running 状态了,证明应用已经部署成功了,我们下面使用NodePort方式在浏览器访问验证一下是否部署成功,如果是用了ingress就使用域名进行访问。
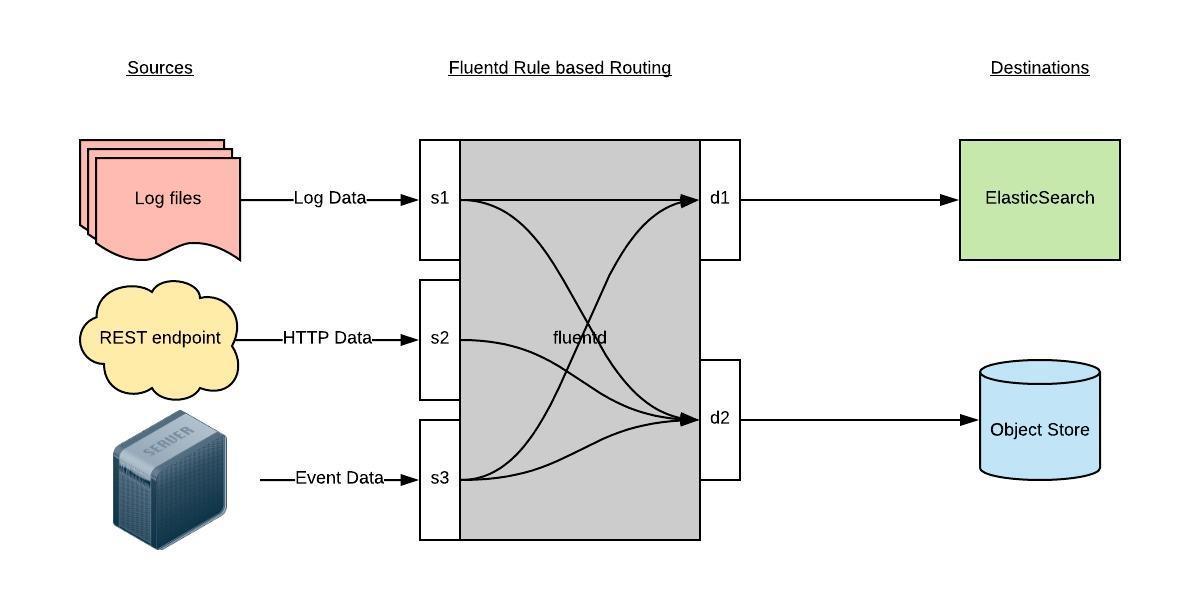
三、部署Fluentd服务 Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少。另外一个工具 Fluent-bit 更轻量级,占用资源更少。但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,这里我们使用 Fluentd 来作为日志收集工具。
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
首先 Fluentd 从多个日志源获取数据; 结构化并且标记这些数据; 然后根据匹配的标签将数据发送到多个目标服务去。
3.1 日志源和路由配置示例 日志源配置 一般来说我们是通过一个配置文件来告诉 Fluentd 如何采集、处理数据的,下面简单和大家介绍下 Fluentd 的配置方法。比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
1 2 3 4 5 6 7 8 9 10 <source > @id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/fluentd-containers.log.pos time_format %Y-%m-%dT%H:%M:%S.%NZ tag raw.kubernetes.* format json read_from_head true </source>
上面配置部分参数说明如下:
id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据;
type:Fluentd 内置的指令,tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据;
path:tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录;
pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集;
tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <match **> @id elasticsearch @type elasticsearch @log_level info include_tag_key true type_name fluentd host "#{ENV['OUTPUT_HOST']}" port "#{ENV['OUTPUT_PORT']}" logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}" queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}" overflow_action block </buffer>
match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成 **。
id:目标的一个唯一标识符。
type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
log_level:指定要捕获的日志级别,我们这里配置成info ,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。
host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为 true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。
Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO
3.2 Fluentd的部署 要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。当然可以直接使用 Helm 来进行一键安装,为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
首先需要通过 ConfigMap 对象来指定 Fluentd 配置文件,ConfigMap资源对象的文件fluentd-es-configmap.yaml(内容过长,请大家自己去查看)。fluentd-es-configmap.yaml 文件中配置了 docker容器日志目录以及 docker、kubelet 应用的日志的收集,收集到数据经过处理后发送到 elasticsearch-logging:9200 服务。DasemonSet 资源对象文件fluentd-es-ds.yaml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 [root@k8s-node01 tmp] apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v3.0.2 namespace: kube-system labels: k8s-app: fluentd-es version: v3.0.2 addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v3.0.2 template: metadata: labels: k8s-app: fluentd-es version: v3.0.2 annotations: seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: quay.io/fluentd_elasticsearch/fluentd:v3.0.2 env : - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d ports: - containerPort: 24231 name: prometheus protocol: TCP livenessProbe: tcpSocket: port: prometheus initialDelaySeconds: 5 timeoutSeconds: 10 readinessProbe: tcpSocket: port: prometheus initialDelaySeconds: 5 timeoutSeconds: 10 tolerations: - key: node-role.kubernetes.io/master operator: "Exists" effect: "NoSchedule" terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
上面创建的 ConfigMap 资源对象通过 volumes 被挂载到了 Fluentd 容器中。如果你想灵活控制哪些节点的日志可以被收集,你可以添加一个 nodSelector 属性;然后给相应的节点打上标签即可,这里我们采用默认配置:
1 2 nodeSelector: beta.kubernetes.io/fluentd-ds-ready: "true"
如果你的集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点;要想收集 master 节点的日志,需要添加上容忍:
1 2 3 4 tolerations: - key: node-role.kubernetes.io/master operator: "Exists" effect: "NoSchedule"
另外需要注意的地方是,如果安装docker时更改了 docker 的根目录需要修改 volumes.name.varlibdockercontainers这个里面的值
1 2 3 4 5 6 7 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers
应用资源清单并验证
1 2 3 4 5 6 [root@k8s-node01 tmp] [root@k8s-node01 tmp] [root@k8s-node01 tmp] fluentd-es-v3.0.2-gknqm 1/1 Running 0 1m fluentd-es-v3.0.2-gv5zt 1/1 Running 0 1m fluentd-es-v3.0.2-x4zpl 1/1 Running 0 1m
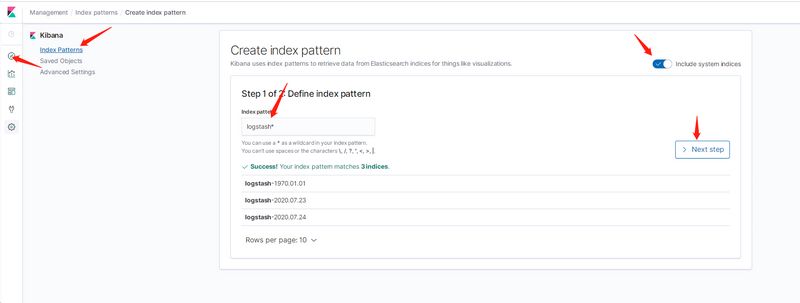
3.3 配置Kibana数据源并查询数据 Fluentd 启动成功后,我们可以前往 Kibana 的 Dashboard 页面中,点击左侧的Discover,可以看到如下配置页面:
这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中采集的日志使用的是 logstash 格式,这里只需要在文本框中输入logstash*即可匹配到 Elasticsearch 集群中的所有日志数据,然后点击下一步,进入以下页面:
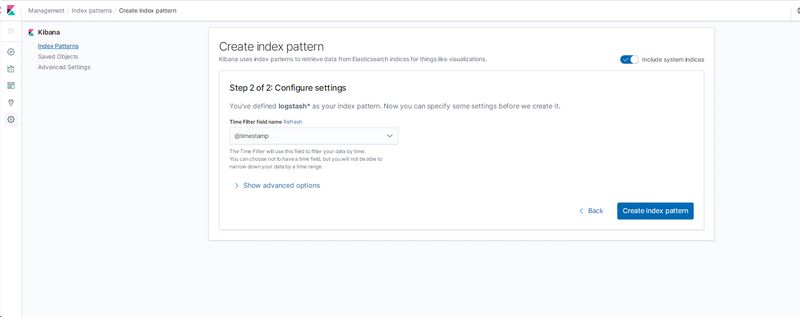
然后点击下一步、在下拉列表中,选择@timestamp字段。然后点击Create index pattern,创建完成后,点击左侧导航菜单中的Discover,然后就可以看到一些直方图和最近采集到的日志数据了:
3.4 Fluentd数据收集测试 现在我们来将下面的计数器应用部署到集群中,并在 Kibana 中来查找该日志数据。我们新建 fluentd-test.yaml 文件,文件内容如下:
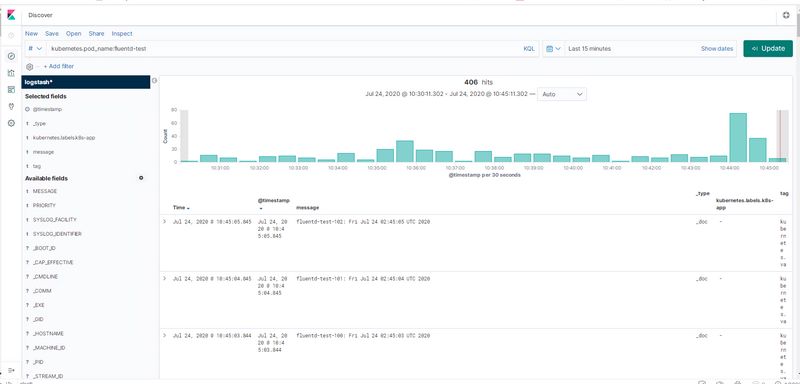
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@k8s-node01 tmp] apiVersion: v1 kind: Pod metadata: name: fluentd-test spec: containers: - name: count image: busybox args: [/bin/sh, -c, 'i=0; while true; do echo "fluentd-test-$i: $(date)"; i=$((i+1)); sleep 1; done' ] [root@k8s-node01 tmp] pod/fluentd-test created [root@k8s-node01 tmp] NAME READY STATUS RESTARTS AGE fluentd-test 1/1 Running 0 13s [root@k8s-node01 tmp] fluentd-test-0: Fri Jul 24 02:43:23 UTC 2020 fluentd-test-1: Fri Jul 24 02:43:24 UTC 2020 fluentd-test-2: Fri Jul 24 02:43:25 UTC 2020 ······
Pod 创建并运行后,我们回到 Kibana Dashboard 页面,在上面的Discover页面搜索栏中输入kubernetes.pod_name:fluentd-test,就可以过滤 Pod 名为 fluentd-test 的日志数据:
当然,我们也可以通过其他元数据来过滤日志数据,比如你可以单击任何日志条目以查看其他元数据,如容器名称,Kubernetes 节点,命名空间等。到这里,我们就在 Kubernetes 集群上成功部署了 EFK ,要了解如何使用 Kibana 进行日志数据分析,可以参考 Kibana 用户指南文档:https://www.elastic.co/guide/en/kibana/current/index.html。对于在生产环境上使用 Elaticsearch 或者 Fluentd,还需要结合实际的环境做一系列的优化工作