十四、资源监控指标 14.1 核心指标监控metrics-server 在最初的系统资源监控,是通过cAdvisor去收集单个节点以及相关Pod资源的指标数据,但是这一功能仅能够满足单个节点,在集群日益庞大的过程中,该功能就显得low爆了。于是将各个节点的指标数据进行汇聚并通过一个借口进行向外暴露传送是必要的。
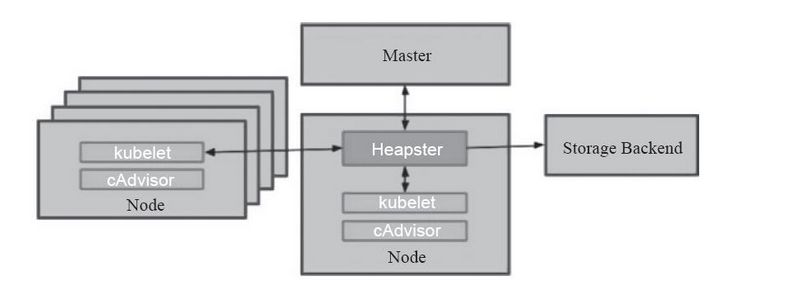
Heapster就是这样的一种方式,通过为集群提供指标API和实现并进行监控,它是集群级别的监控和事件数据的聚合工具,但是一个完备的Heapster监控体系是需要进行数据存储的,为此其解决方案就是引入了Influxdb作为后端数据的持久存储,Grafana作为可视化的接口。原理就是Heapster从各个节点上的cAdvisor采集数据并存储到Influxdb中,再由Grafana展示。原理图如下:
时代在变迁,陈旧的东西将会被淘汰,由于功能和系统发展的需求,Heapster无法满足k8s系统监控的需求,为此在Kubernetes 1.7版本以后引入了自定义指标(custom metrics API),在1.8版本引入了资源指标(resource metrics API)。逐渐地Heapster用于提供核心指标API的功能也被聚合方式的指标API服务器metrics-server所替代。
在新一代的Kubernetes指标监控体系当中主要由核心指标流水线和监控指标流水线组成:
核心指标流水线:是指由kubelet、、metrics-server以及由API server提供的api组成,它们可以为K8S系统提供核心指标,从而了解并操作集群内部组件和程序。其中相关的指标包括CPU的累积使用率、内存实时使用率,Pod资源占用率以及容器磁盘占用率等等。其中核心指标的获取原先是由heapster进行收集,但是在1.11版本之后已经被废弃,从而由新一代的metrics-server所代替对核心指标的汇聚。核心指标的收集是必要的。如下图:
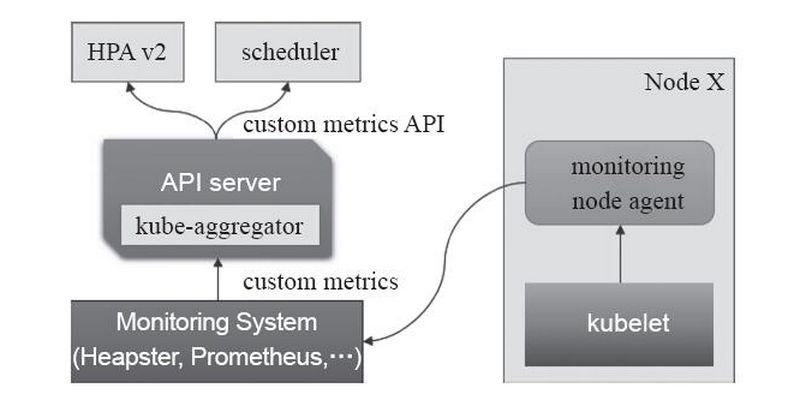
监控指标流水线:用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA。它们包含核心指标以及许多非核心指标,其中由于非核心指标本身不能被Kubernetes所解析,此时就需要依赖于用户选择第三方解决方案。如下图:
一个可以同时使用资源指标API和自定义指标API的组件是HPAv2,其实现了通过观察指标实现自动扩容和缩容。而目前资源指标API的实现主流是metrics-server。
自1.8版本后,容器的cpu和内存资源占用利用率都可以通过客户端指标API直接调用,从而获取资源使用情况,要知道的是API本身并不存储任何指标数据,仅仅提供资源占用率的实时监测数据。
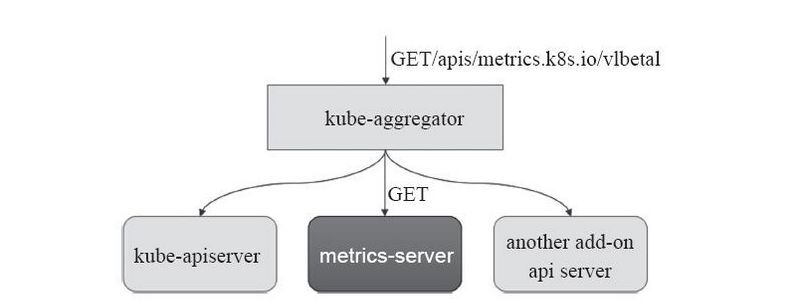
资源指标和其他的API指标并没有啥区别,它是通过API Server的URL路径/apis/metrics.k8s.io/进行存取,只有在k8s集群内部署了metrics-server应用才能只用API,其简单的结构图如下:
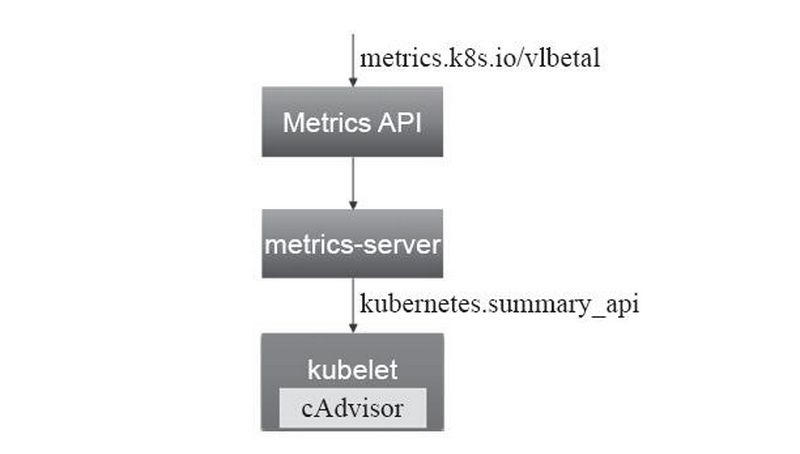
Heapster。 Metrics Server 通过 Kubernetes 聚合 器( kube- aggregator) 注册 到 主 API Server 之上, 而后 基于 kubelet 的 Summary API 收集 每个 节 点上 的 指标 数据, 并将 它们 存储 于 内存 中 然后 以 指标 API 格式 提供,如下图:
Metrics Server基于 内存 存储, 重 启 后 数据 将 全部 丢失, 而且 它 仅能 留存 最近 收集 到 的 指标 数据, 因此, 如果 用户 期望 访问 历史 数据, 就不 得不 借助于 第三方 的 监控 系统( 如 Prometheus 等)。
一般说来, Metrics Server 在 每个 集群 中 仅 会 运行 一个 实例, 启动 时, 它将 自动 初始化 与 各 节点 的 连接, 因此 出于 安全 方面 的 考虑, 它 需要 运行 于 普通 节点 而非 Master 主机 之上。 直接 使用 项目 本身 提供 的 资源 配置 清单 即 能 轻松 完成 metrics- server 的 部署。
部署yaml连接:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
14.1.1 metrics-server部署 1.下载部署需要用到的yaml文件到本地
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@k8s-master k8s-yaml]$ mkdir metrics-server [root@k8s-master k8s-yaml]$ cd metrics-server/ [root@k8s-master metrics-server]$ cat > list.txt <<EOF auth-delegator.yaml auth-reader.yaml metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml EOF [root@k8s-master metrics-server]$ for i in `cat ./list.txt`;do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/metrics-server/$i ;done [root@k8s-master metrics-server]$ ll total 32 -rw-r--r-- 1 root root 398 Jul 16 13:33 auth-delegator.yaml -rw-r--r-- 1 root root 419 Jul 16 13:33 auth-reader.yaml -rw-r--r-- 1 root root 3335 Jul 16 13:13 components.yaml -rw-r--r-- 1 root root 141 Jul 16 13:31 list.txt -rw-r--r-- 1 root root 388 Jul 16 13:33 metrics-apiservice.yaml -rw-r--r-- 1 root root 3360 Jul 16 13:33 metrics-server-deployment.yaml -rw-r--r-- 1 root root 336 Jul 16 13:33 metrics-server-service.yaml -rw-r--r-- 1 root root 844 Jul 16 13:33 resource-reader.yaml
2.修改deploument.yaml里面的一些参数并应用yaml配置清单
由于某些原因,有些镜像在国内无法下载,所以我们需要修改配置文件中镜像下载地址,要注意红色字体为镜像运行的参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [root@k8s-master metrics-server] ······ containers: - name: metrics-server image: k8s.gcr.io/metrics-server-amd64:v0.3.6 command : - /metrics-server - --metric-resolution=30s - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP - --kubelet-insecure-tls ······ ······ - name: metrics-server-nanny image: k8s.gcr.io/addon-resizer:1.8.11 command : - /pod_nanny - --config-dir=/etc/config - --cpu=100m - --extra-cpu=0.5m - --memory=100Mi - --extra-memory=50Mi - --threshold=5 - --deployment=metrics-server-v0.3.6 - --container=metrics-server - --poll-period=300000 - --estimator=exponential - --minClusterSize=10 - --use-metrics=true ······ [root@k8s-master metrics-server]$ vim resource-reader.yaml .... rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces [root@k8s-master metrics]$ kubectl apply -f . [root@k8s-master metrics]$ kubectl api-versions |grep metrics metrics.k8s.io/v1beta1 [root@k8s-master metrics]$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" {"kind" :"NodeMetricsList" ,"apiVersion" :"metrics.k8s.io/v1beta1" ,"metadata" :{"selfLink" :"/apis/metrics.k8s.io/v1beta1/nodes" },"items" :[{"metadata" :{"name" :"k8s-master" ,"selfLink" :"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master" ,"creationTimestamp" :"2019-03-22T08:12:44Z" },"timestamp" :"2019-03-22T08:12:10Z" ,"window" :"30s" ,"usage" :{"cpu" :"522536968n" ,"memory" :"1198508Ki" }},{"metadata" :{"name" :"k8s-node01" ,"selfLink" :"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node01" ,"creationTimestamp" :"2019-03-22T08:12:44Z" },"timestamp" :"2019-03-22T08:12:08Z" ,"window" :"30s" ,"usage" :{"cpu" :"70374658n" ,"memory" :"525544Ki" }},{"metadata" :{"name" :"k8s-node02" ,"selfLink" :"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node02" ,"creationTimestamp" :"2019-03-22T08:12:44Z" },"timestamp" :"2019-03-22T08:12:11Z" ,"window" :"30s" ,"usage" :{"cpu" :"68437841n" ,"memory" :"519756Ki" }}]} [root@k8s-master metrics]$ kubectl get pods -n kube-system |grep metrics metrics-server-v0.3.1-5977577c75-wrcrt 2/2 Running 0 22m
以上如果内容没有做修改的话,会出现容器跑不起来一直处于CrashLoopBackOff状态,或者出现权限拒绝的问题。可以通过kubectl logs进行查看相关的日志。下面使用kubectl top命令进行查看资源信息:
1 2 3 4 5 6 7 8 9 10 [root@k8s-master metrics]$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master 497m 12% 1184Mi 68% k8s-node01 81m 8% 507Mi 58% k8s-node02 63m 6% 505Mi 57% [root@k8s-master metrics]$ kubectl top pod -l k8s-app=kube-dns --containers=true -n kube-system POD NAME CPU(cores) MEMORY(bytes) coredns-78fcdf6894-nmcmz coredns 5m 12Mi coredns-78fcdf6894-p5pfm coredns 5m 15Mi
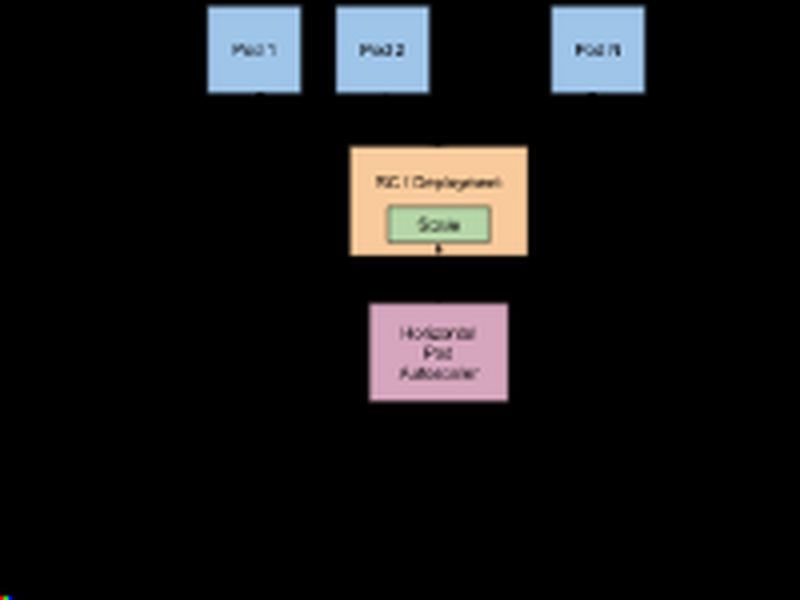
14.2 HPA弹性伸缩 Pod 水平自动伸缩(Horizontal Pod Autoscaler)特性, 可以基于CPU利用率自动伸缩 replication controller、deployment和 replica set 中的 pod 数量,(除了 CPU 利用率)也可以 基于其他应程序提供的度量指标custom metrics 。 pod 自动缩放不适用于无法缩放的对象,比如 DaemonSets。
Pod 水平自动伸缩特性由 Kubernetes API 资源和控制器实现。资源决定了控制器的行为。 控制器会周期性的获取平均 CPU 利用率,并与目标值相比较后来调整 replication controller 或 deployment 中的副本数量。
HPA工作机制
Pod 水平自动伸缩的实现是一个控制循环,由 controller manager 的 --horizontal-pod-autoscaler-sync-period 参数 指定周期(默认值为15秒)。
每个周期内,controller manager 根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。 controller manager 可以从 resource metrics API(每个pod 资源指标)和 custom metrics API(其他指标)获取指标。
对于每个 pod 的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定 的 pod 的指标,然后,如果设置了目标使用率,控制器获取每个 pod 中的容器资源使用情况,并计算资源使用率。 如果使用原始值,将直接使用原始数据(不再计算百分比)。 然后,控制器根据平均的资源使用率或原始值计算出缩放的比例,进而计算出目标副本数。
需要注意的是,如果 pod 某些容器不支持资源采集,那么控制器将不会使用该 pod 的 CPU 使用率。 下面的算法细节 章节将会介绍详细的算法。
如果 pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。
如果pod 使用对象指标和外部指标(每个指标描述一个对象信息)。 这个指标将直接跟据目标设定值相比较,并生成一个上面提到的缩放比例。在 autoscaling/v2beta2 版本API中, 这个指标也可以根据 pod 数量平分后再计算。
HPA算法细节 从最基本的角度来看,pod 水平自动缩放控制器跟据当前指标和期望指标来计算缩放比例。
1 期望副本数 = ceil[当前副本数 * ( 当前指标 / 期望指标 )]
下面举一个实际例子进行上述公式的阐述,假设存在一个叫A的Deployment,包含3个Pod,每个副本的Request值是1核,当前3个Pod的CPU利用率分别是60%、70%与80%,此时我们设置HPA阈值为50%,最小副本为3,最大副本为10。接下来我们将上述的数据带入公式中。
总的Pod的利用率是60%+70%+80% = 210%。
当前的Target是3。
算式的结果是70%,大于阈值的50%阈值,因此当前的Target数目过小,需要进行扩容。
重新设置Target值为5,此时算式的结果为42%低于50%,判断还需要扩容两个容器。
此时HPA设置Replicas为5,进行Pod的水平扩容。
经过上面的推演,可以协助开发者快速理解HPA最核心的原理,不过上面的推演结果和实际情况下是有所出入的,如果开发者进行试验的话,会发现Replicas最终的结果是6而不是5。这是由于HPA中一些细节的处理导致的,主要包含如下三个主要的方面:
噪声处理
通过上面的公式可以发现,Target的数目很大程度上会影响最终的结果,而在Kubernetes中,无论是变更或者升级,都更倾向于使用Recreate而不是Restart的方式进行处理。这就导致了在Deployment的生命周期中,可能会出现某一个时间,Target会由于计算了Starting或者Stopping的的Pod而变得很大。这就会给HPA的计算带来非常大的噪声,在HPA Controller的计算中,如果发现当前的对象存在Starting或者Stopping的Pod会直接跳过当前的计算周期,等待状态都变为Running再进行计算。
冷却周期
在弹性伸缩中,冷却周期是不能逃避的一个话题,很多时候我们期望快速弹出与快速回收,而另一方面,我们又不希望集群震荡,所以一个弹性伸缩活动冷却周期的具体数值是多少,一直被开发者所挑战。在HPA中,默认的扩容冷却周期是3分钟,缩容冷却周期是5分钟。
边界值计算
我们回到刚才的计算公式,第一次我们算出需要弹出的容器数目是5,此时扩容后整体的负载是42%,但是我们似乎忽略了一个问题,一个全新的Pod启动会不会自己就占用了部分资源?此外,8%的缓冲区是否就能够缓解整体的负载情况,要知道当一次弹性扩容完成后,下一次扩容要最少等待3分钟才可以继续扩容。为了解决这些问题,HPA引入了边界值△,目前在计算边界条件时,会自动加入10%的缓冲,这也是为什么在刚才的例子中最终的计算结果为6的原因。
14.2.1 根据cpu使用率自动HPA
注意:下面要执行的操作需要根据上面metrics-server的部署步骤,部署好metrics-server。
部署一个deploy限制cpu资源,并创建一个svc关联deploy后面进行压测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 [root@k8s-master HPA]$ vim deploy-mynginx.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: my-nginx name: my-nginx spec: replicas: 1 selector: matchLabels: app: my-nginx template: metadata: labels: app: my-nginx spec: containers: - image: putianhui/myapp:v1 name: myapp resources: limits: cpu: 100m --- apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: app: my-nginx name: mynginx-svc spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: my-nginx type : ClusterIP [root@k8s-master HPA]$ kubectl apply -f deploy-mynginx.yaml deployment.apps/my-nginx created [root@k8s-master HPA]$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE my-nginx 1/1 1 1 20s [root@k8s-master HPA]$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 18h mynginx-svc ClusterIP 10.106.91.235 <none> 80/TCP 5s [root@k8s-master HPA]$ kubectl get pods NAME READY STATUS RESTARTS AGE my-nginx-6f64877f46-bp4vs 1/1 Running 0 50s
2.创建一个HPA控制器关联上面的deploy
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@k8s-master HPA]$ kubectl autoscale deployment my-nginx --max=10 --min=1 --cpu-percent=50 horizontalpodautoscaler.autoscaling/my-nginx autoscaled [root@k8s-master HPA]$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE my-nginx Deployment/my-nginx <unknown>/50% 1 10 0 6s
3.启动一个busybox容器对上面的pod进行压测,查看是否自动扩缩容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 [root@k8s-master HPA]$ kubectl get svc |grep mynginx-svc mynginx-svc ClusterIP 10.106.91.235 <none> 80/TCP 4m [root@k8s-node01 /]$ kubectl run -it --image=busybox --image-pull-policy=IfNotPresent -- sh If you don't see a command prompt, try pressing enter. / # while true;do wget http://10.106.91.235/index.html;sleep 0.1;done Connecting to 10.106.91.235 (10.106.91.235:80) wget: can' t open 'index.html' : File existsConnecting to 10.106.91.235 (10.106.91.235:80) wget: can't open ' index.html': File exists # 查看hpa动态 [root@k8s-master HPA]$ kubectl get hpa -w # 每15秒更新一次动态,自动计算需要3个副本。 NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE my-nginx Deployment/my-nginx 3%/50% 1 10 1 11m my-nginx Deployment/my-nginx 100%/50% 1 10 1 11m my-nginx Deployment/my-nginx 100%/50% 1 10 2 11m my-nginx Deployment/my-nginx 97%/50% 1 10 2 12m my-nginx Deployment/my-nginx 57%/50% 1 10 2 12m my-nginx Deployment/my-nginx 57%/50% 1 10 3 12m my-nginx Deployment/my-nginx 55%/50% 1 10 3 13m my-nginx Deployment/my-nginx 41%/50% 1 10 3 13m # 查看Pod动态(自动扩容两个副本) [root@k8s-node02 /]$ kubectl get pods -w NAME READY STATUS RESTARTS AGE my-nginx-6f64877f46-bp4vs 1/1 Running 0 14m my-nginx-6f64877f46-2d9cx 0/1 ContainerCreating 0 0s my-nginx-6f64877f46-2d9cx 1/1 Running 0 3s my-nginx-6f64877f46-tw8xb 0/1 ContainerCreating 0 0s my-nginx-6f64877f46-tw8xb 1/1 Running 0 3s
4.停止对pod压测,查看是否会自动缩
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Connecting to 10.106.91.235 (10.106.91.235:80) wget: can't open ' index.html': File exists ^CConnecting to 10.106.91.235 (10.106.91.235:80) wget: can' t open 'index.html' : File exists/ [root@k8s-master HPA]$ kubectl get hpa -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE my-nginx Deployment/my-nginx 41%/50% 1 10 3 29m my-nginx Deployment/my-nginx 5%/50% 1 10 3 29m my-nginx Deployment/my-nginx 0%/50% 1 10 3 30m my-nginx Deployment/my-nginx 0%/50% 1 10 3 34m my-nginx Deployment/my-nginx 0%/50% 1 10 3 34m my-nginx Deployment/my-nginx 0%/50% 1 10 1 34m my-nginx Deployment/my-nginx 0%/50% 1 10 1 34m [root@k8s-node02 /]$ kubectl get pods -w NAME READY STATUS RESTARTS AGE my-nginx-6f64877f46-2d9cx 1/1 Running 0 17m my-nginx-6f64877f46-bp4vs 1/1 Running 0 34m my-nginx-6f64877f46-tw8xb 1/1 Running 0 16m my-nginx-6f64877f46-tw8xb 1/1 Terminating 0 21m my-nginx-6f64877f46-bp4vs 1/1 Terminating 0 38m
14.2.2 根据内存用率自动HPA
注意:基于内存或者自定义指标的HPA需要autoscaling/v2beta1版本及以上 (命令行kubectl autoscale这种方式创建的hpa是v1版本的)
部署一个deploy限制内存资源,并创建一个svc关联deploy后面进行压测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 [root@k8s-master HPA]$ kubectl delete hpa my-nginx horizontalpodautoscaler.autoscaling "my-nginx" deleted [root@k8s-master HPA]$ kubectl delete svc mynginx-svc service "mynginx-svc" deleted [root@k8s-master HPA]$ kubectl delete deployments.apps my-nginx deployment.apps "my-nginx" deleted [root@k8s-master HPA]$ vim deploy-mynginx-memory.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: my-nginx name: my-nginx spec: replicas: 1 selector: matchLabels: app: my-nginx template: metadata: labels: app: my-nginx spec: containers: - image: putianhui/myapp:v1 name: myapp resources: limits: memory: 100Mi --- apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: app: my-nginx name: mynginx-svc spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: my-nginx type : ClusterIP [root@k8s-master HPA]$ kubectl apply -f deploy-mynginx-memory.yaml deployment.apps/my-nginx created [root@k8s-master HPA]$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE my-nginx 1/1 1 1 20s [root@k8s-master HPA]$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19h mynginx-svc ClusterIP 10.101.3.114 <none> 80/TCP 74s [root@k8s-master HPA]$ kubectl get pods NAME READY STATUS RESTARTS AGE my-nginx-658c9f6c6-k4rjz 1/1 Running 0 92s [root@k8s-master HPA]$ kubectl top pods NAME CPU(cores) MEMORY(bytes) my-nginx-658c9f6c6-k4rjz 0m 1Mi
2.创建一个HPA控制器关联上面的deploy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@k8s-master HPA]$ vim mynginx-hpa.yaml apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: mynginx-hpa spec: maxReplicas: 10 minReplicas: 1 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-nginx metrics: - type : Resource resource: name: memory targetAverageUtilization: 50 [root@k8s-master HPA]$ kubectl apply -f mynginx-hpa.yaml horizontalpodautoscaler.autoscaling/mynginx-hpa created [root@k8s-master HPA]$ kubectl get hpa mynginx-hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE mynginx-hpa Deployment/my-nginx 1%/50% 1 10 1 2m23s
3.启动一个busybox容器对上面的pod进行压测,查看是否自动扩缩容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@k8s-node01 ~]$ kubectl get pods NAME READY STATUS RESTARTS AGE my-nginx-658c9f6c6-k4rjz 1/1 Running 0 26m sh 1/1 Running 1 116m [root@k8s-node01 ~]$ kubectl exec -it my-nginx-658c9f6c6-k4rjz -- sh / / [root@k8s-master ~]$ kubectl get hpa -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE mynginx-hpa Deployment/my-nginx 1%/50% 1 10 1 18m mynginx-hpa Deployment/my-nginx 71%/50% 1 10 2 18m mynginx-hpa Deployment/my-nginx 26%/50% 1 10 2 19m [root@k8s-node02 ~]$ kubectl get pods -w NAME READY STATUS RESTARTS AGE my-nginx-658c9f6c6-k4rjz 1/1 Running 0 26m my-nginx-658c9f6c6-v2sgf 0/1 ContainerCreating 0 0s my-nginx-658c9f6c6-v2sgf 1/1 Running 0 8s