环境介绍及组件版本
我这里是做实验,所有组件全部署在一台机器上(包括日志收集端),生产部署根据需求将各组件分别部署(promtail日志收集端是需要每个需要日志收集的服务器都部署的)。
组件信息
服务名称
版本
备注
Promtail
v2.7.0
服务端收集日志agent输出到loki存储,类似filebeat
Loki
v2.7.0
存储日志和查询日志
Grafana
v9.2.7
用于查询日志及配置日志告警规则,将告警发送至webhook
PrometheusAlert
v4.8.2
告警通知中心用于暴露webhook,将Grafana推送的告警信息模板格式化后发送至飞书
Loki介绍 特点
围绕日志标签构建索引,而不是像es一样进行全文索引
多租户:通过tenant ID实现多租户,如果关闭多租户, 则默认唯一租户为fake
部署模式
单进程模式:所有的组件运行在一个进程中,适用于测试环境或者较小的生产环境
微服务可扩展模式:各组件单独运行,可水平伸缩扩展
组件
Distributor
负责处理客户端的日志写入,负责接收日志数据,然后将其拆分成多个块,并行的发送给ingester
Distributor通过GRPC协议与Ingester进行通信
Hashing
Distributor通过一致性哈希和可配置因子来确定哪些Ingester服务的实例应该接收日志数据hash基于日志标签和tenant IDconsole中的hashring用于实现一致性hash,所有Ingester都使用自己拥有的一组令牌注册到console中,Distributor通过找到日志hash值最匹配的令牌并将日志数据发送给该令牌的所有者
Ingester
负责将日志数据写入持久化后端(S3,OSS)
Ingester负责所有的日志行有序
Ingester负责所有的日志行按升序排序,如果收到乱序的日志行,将拒绝并报错
来自每一组唯一标签的日志在内存中被构建为“块”,然后被刷新到备份存储后端。
如果ingester进程奔溃,内存中构建的块的数据未刷写到磁盘,则会丢失
Querier:LogQL首先尝试查询所有Ingester的内存数据,然后再从后端存储加载数据。
Chunk Store
块存储是Loki长期数据存储,支持交互式查询和持续写入包含(块索引以及块数据本身的键值存储)
注意: 块存储不是单独的服务,而是嵌入到需要访问的Loki数据的服务中的库:Querier和Ingester
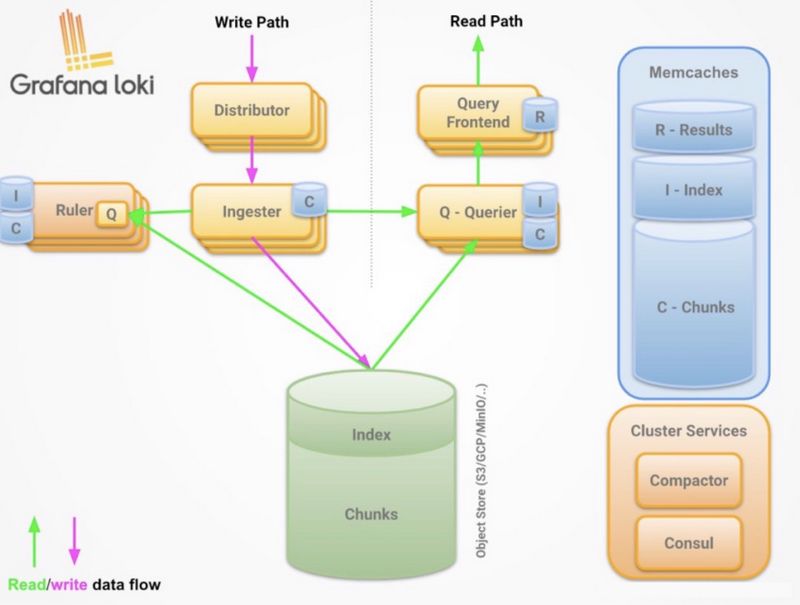
Loki架构图
数据写入
Distributor负责接收日志数据,然后拆分为多个块,并行的发送给IngesterIngester接收Distributor发送的数据块,缓存在内存中, 同时定时刷写进持久化存储Chunk Store中
数据查询
Ingester接收Querier查询请求,根据块索引查询指定的块,如果内存中没有,将从持久化存储chunk Store中查找数据,并返回
开始安装服务 本文档部署使用单进程模式进行部署的,官网有K8s下Helm部署、Docker部署等其他部署模式,请自行参考学习。
安装supervisor 我这里二进制部署各个服务,使用了supervisor来管理各个服务的启停,所以我这里安装下supervisor,如果你使用二进制直接启停此步骤可以忽略,详细的supervisor使用文档点我查看博客
安装supervisor
1 $ yum install -y epel-release supervisor unzip
修改supervisor配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ vim /etc/supervisord.conf [unix_http_server] file=/var/run/supervisor/supervisor.sock ; (the path to the socket file) chmod =0700 ; sockef file mode (default 0700)[inet_http_server] ; inet (TCP) server disabled by default port=*:9001 ; (ip_address:port specifier, *:port for all iface) username=admin ; (default is no username (open server)) password=admin ; (default is no password (open server)) [supervisord] logfile=/var/log/supervisor/supervisord.log ; (main log file;default $CWD /supervisord.log) logfile_maxbytes=50MB ; (max main logfile bytes b4 rotation;default 50MB) logfile_backups=10 ; (num of main logfile rotation backups;default 10) loglevel=info ; (log level;default info; others: debug,warn,trace) pidfile=/var/run/supervisord.pid ; (supervisord pidfile;default supervisord.pid) nodaemon=false ; (start in foreground if true ;default false ) minfds=1024 ; (min. avail startup file descriptors;default 1024) minprocs=200 ; (min. avail process descriptors;default 200) [rpcinterface:supervisor] supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface [supervisorctl] serverurl=unix:///var/run/supervisor/supervisor.sock ; use a unix:// URL for a unix socket serverurl=http://127.0.0.1:9001 ; use an http:// url to specify an inet socket username=admin ; should be same as http_username if set password=admin ; should be same as http_password if set [include] files = supervisord.d/*.ini
启动supervisord服务,服务启动成功后后期托管的服务可以通过web来管理,访问http://本机ip:9001 账号密码默认admin/admin
1 $ systemctl enable supervisord && systemctl start supervisord
安装Loki 自行在Github下载 对应架构和版本的二进制服务包即可
创建loki的数据目录,下载二进制包解压并重命名
1 2 3 4 5 6 7 8 $ mkdir /data/loki/{data,log } -p && cd /data/loki/ $ wget https://github.com/grafana/loki/releases/download/v2.7.0/loki-linux-amd64.zip $ unzip loki-linux-amd64.zip && mv loki-linux-amd64 loki
创建loki配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 $ cat > loki-config.yaml<<EOF auth_enabled: false server: http_listen_port: 3100 grpc_listen_port: 9096 common: path_prefix: /data/loki/data storage: filesystem: chunks_directory: /data/loki/data/chunks rules_directory: /data/loki/data/rules replication_factor: 1 ring: instance_addr: 127.0.0.1 kvstore: store: inmemory schema_config: configs: - from: 2020-10-24 store: boltdb-shipper object_store: filesystem schema: v11 index: prefix: index_ period: 24h ruler: alertmanager_url: http://localhost:9093 EOF
创建supervisor托管启停Loki服务的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cat >/etc/supervisord.d/loki.ini<<EOF ;项目名 [program:loki] ;脚本目录 directory=/data/loki ;脚本执行命令 command=/data/loki/loki --config.file=/data/loki/loki-config.yaml ;supervisor启动的时候是否随着同时启动,默认True autostart=true ;当程序exit的时候自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启,false是永不重启,true是自动重启 autorestart=true ; 启动失败自动重试次数,默认是3 startretries=3 ;这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启动成功了。默认值为1 startsecs=1 ;程序启动使用的用户身份 user = root ;stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件) stdout_logfile=/data/loki/log/loki.out ;把stderr重定向到stdout,默认 false redirect_stderr = true ;stdout日志文件大小,默认 50MB stdout_logfile_maxbytes = 20MB ;stdout日志文件备份数 stdout_logfile_backups = 10 EOF
supervisor启动loki服务,启动成功后loki服务的地址就是http://本机ip:3100
1 2 $ supervisorctl update && supervisorctl start loki && supervisorctl status loki RUNNING pid 18598, uptime 0:00:16
安装Promtail 自行在Github下载 对应架构和版本的二进制服务包即可
创建Promtail的数据目录,下载二进制包解压并重命名
1 2 3 4 5 6 7 8 $ mkdir /data/promtail/{data,log } -p && cd /data/promtail/ $ wget https://github.com/grafana/loki/releases/download/v2.7.0/promtail-linux-amd64.zip $ unzip promtail-linux-amd64.zip && mv promtail-linux-amd64 promtail
创建promtai配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 $ cat >>promtail-local-config.yaml<<EOF server: # http端口,默认即可 http_listen_port: 9080 grpc_listen_port: 0 # 解决大量日志报trying to send message larger than max错误问题 grpc_server_max_concurrent_streams: 500 grpc_server_max_recv_msg_size: 10000000 grpc_server_max_send_msg_size: 10000000 positions: # 监听的日志文件已经读取的行偏移量存储文件地址 filename: /tmp/positions.yaml clients: # 这里是你的loki服务器地址 - url: http://192.168.0.191:3100/loki/api/v1/push # 配置要收集的日志 scrape_configs: # 配置收集的任务名称(自定义即可,后面可以根据这个名称过滤查看日志),我这里收集的是系统日志。 - job_name: system_log static_configs: - targets: - localhost # 给这个日志收集任务打上一些标签,后面可以根据这些标签来过滤日志查看,或者来做告警。 labels: job: system_log host: ops-test-191 team: ops app: system # 被收集的日志路径,这里配置了/var/log/*.log,还有/var/log/cron这种指定的文件,不以.log结尾的日志文件。 __path__: /var/log/{*.log,btmp,cron,dmesg,lastlog,messages,secure,wtmp} # 我这里配置一个收集kafka日志的任务 - job_name: kafka_server static_configs: - targets: - localhost # 给这个任务打标签,方便查看过滤日志 labels: job: kafka_server host: ops-test-191 app: kafka team: ops # kafka日志文件的路径 __path__: /data/kafka/logs/server.log # 这个配置解决kafka这个任务在收集日志时,某条日志出现换行后会分别收集到多行中导致日志丢失解决方法。 pipeline_stages: - match: # 匹配哪些标签 selector: '{job="kafka_server"}' stages: - multiline: # 已这个开头的才认为是新一行 firstline: '^\[' # 等待三秒钟非[开头的行收集到一行中,否则收集到新一行里面去 max_wait_time: 3s EOF
创建supervisor托管启停promtail服务的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cat >/etc/supervisord.d/promtail.ini<<EOF ;项目名 [program:promtai] ;脚本目录 directory=/data/promtail ;脚本执行命令 command=/data/promtail/promtail --config.file=/data/promtail/promtail-local-config.yaml ;supervisor启动的时候是否随着同时启动,默认True autostart=true ;当程序exit的时候自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启,false是永不重启,true是自动重启 autorestart=true ; 启动失败自动重试次数,默认是3 startretries=3 ;这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启动成功了。默认值为1 startsecs=1 ;程序启动使用的用户身份 user = root ;stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件) stdout_logfile=/data/promtail/log/promtail.out ;把stderr重定向到stdout,默认 false redirect_stderr = true ;stdout日志文件大小,默认 50MB stdout_logfile_maxbytes = 20MB ;stdout日志文件备份数 stdout_logfile_backups = 10 EOF
supervisor启动promtail服务
1 2 3 $ supervisorctl update && supervisorctl status loki RUNNING pid 18598, uptime 0:21:50 promtai RUNNING pid 19709, uptime 0:00:05
查看promtail的日志,无报错即启动成功了
1 2 3 4 5 6 $ tail -f /data/promtail/log/promtail.out level=info ts=2022-12-01T03:02:07.777216395Z caller =promtail.go:123 msg="Reloading configuration file" md5sum =939a5b17c2c41c6ac525dcf45e9db654 level=info ts=2022-12-01T03:02:07.778163605Z caller =server.go:323 http=[::]:9080 grpc=[::]:43841 msg="server listening on addresses" level=info ts=2022-12-01T03:02:07.778324042Z caller =main.go:171 msg="Starting Promtail" version="(version=HEAD-1b627d8, branch=HEAD, revision=1b627d880)" level=warn ts=2022-12-01T03:02:07.795982266Z caller =promtail.go:220 msg="enable watchConfig" level=info ts=2022-12-01T03:02:12.796214081Z caller =filetargetmanager.go:352 msg="Adding target" key="/var/log/{*.log,btmp,cron,dmesg,lastlog,messages,secure,wtmp}:{app=\"system\", host=\"ops-test-191\", job=\"system_log\", team=\"ops\"}"
安装Grafana 自行在官网下载 对版本的二进制服务包即可
创建grafana的数据目录,下载二进制包解压并重命名
1 2 3 4 5 6 7 8 $ wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.2.7.linux-amd64.tar.gz $ tar xzvf grafana-enterprise-9.2.7.linux-amd64.tar.gz && mv grafana-9.2.7 /data/grafana $ mkdir -p /data/grafana/log
创建supervisor托管启停grafana服务的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cat >/etc/supervisord.d/grafana.ini<<EOF ;项目名 [program:grafana] ;脚本目录 directory=/data/grafana ;脚本执行命令 command=/data/grafana/bin/grafana-server ;supervisor启动的时候是否随着同时启动,默认True autostart=true ;当程序exit的时候自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启,false是永不重启,true是自动重启 autorestart=true ; 启动失败自动重试次数,默认是3 startretries=3 ;这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启动成功了。默认值为1 startsecs=1 ;程序启动使用的用户身份 user = root ;stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件) stdout_logfile=/data/grafana/log/grafana.out ;把stderr重定向到stdout,默认 false redirect_stderr = true ;stdout日志文件大小,默认 50MB stdout_logfile_maxbytes = 20MB ;stdout日志文件备份数 stdout_logfile_backups = 10 EOF
supervisor启动grafana服务,如有启动失败查看/data/grafana/log/grafana.out日志。
1 2 3 4 5 $ supervisorctl update && supervisorctl status grafana RUNNING pid 20601, uptime 0:00:45 loki RUNNING pid 18598, uptime 0:39:23 promtai RUNNING pid 19709, uptime 0:17:38
grafana服务启动成功后可以通过 http://本机ip:3000 访问,默认账号密码admin/admin,首次登录会提示重置密码,你可以选择Skip跳过或者设置一个新密码都可以。
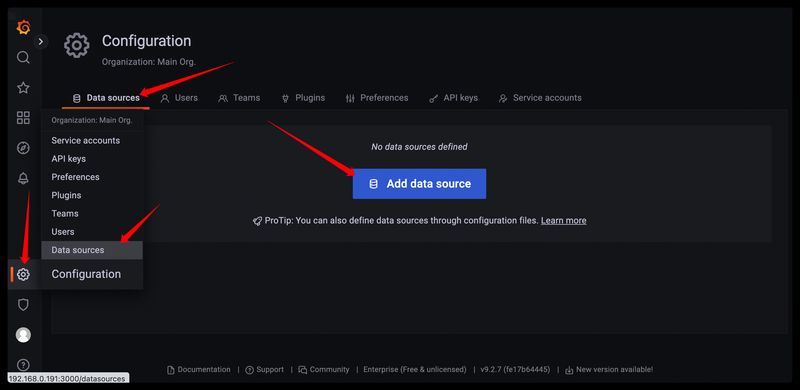
下面配置Grafana添加Loki数据源,然后查看promtail收集到loki中的日志数据。
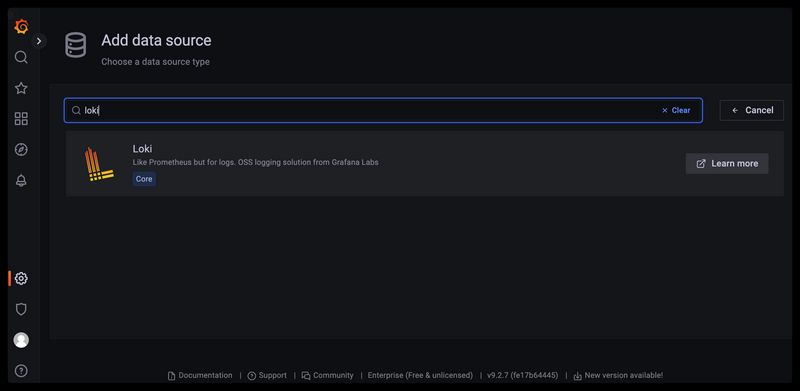
选择loki数据源
输入刚刚安装的loki地址,测试并添加数据源
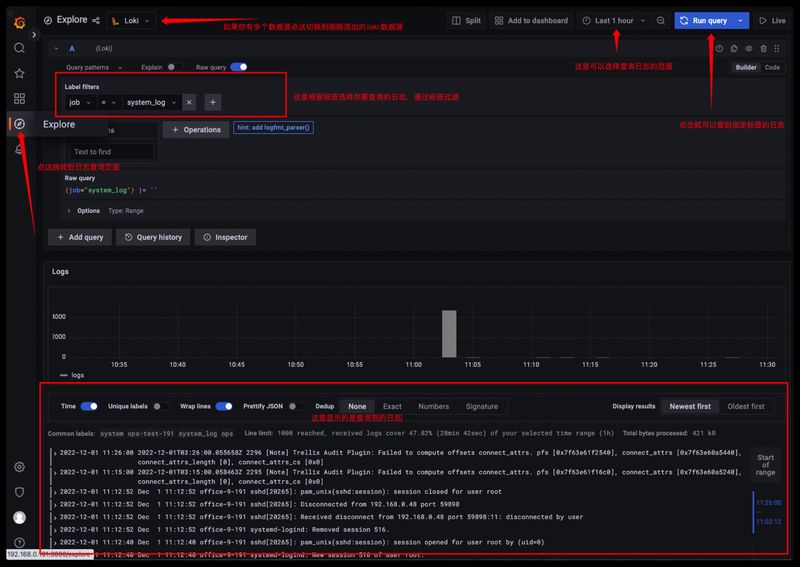
根据日志标签查询日志
安装PrometheusAlert实现告警通知到飞书 自行在Github下载 对应架构和版本的二进制服务包即可,下载二进制包解压并重命名
1 2 3 4 5 6 7 8 $ wget https://github.com/feiyu563/PrometheusAlert/releases/download/v4.8.2/linux.zip $ unzip linux.zip && mv linux /data/PrometheusAlert $ cd /data/PrometheusAlert && chmod +x PrometheusAlert
修改PrometheusAlert配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ cd /data/PrometheusAlert $ vim conf/app.conf ------------- 【下面展示的是我修改的配置,未展示的就是使用的默认配置】 ------------- login_user=admin login_password=putianhui open-feishu=1 fsurl=https://open.feishu.cn/open-apis/bot/hook/xxxxxxxxx
创建supervisor托管启停PrometheusAlert服务的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cat >/etc/supervisord.d/prometheus-alter.ini<<EOF ;项目名 [program:prometheus-alter] ;脚本目录 directory=/data/PrometheusAlert ;脚本执行命令 command=/data/PrometheusAlert/PrometheusAlert ;supervisor启动的时候是否随着同时启动,默认True autostart=true ;当程序exit的时候自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启,false是永不重启,true是自动重启 autorestart=true ; 启动失败自动重试次数,默认是3 startretries=3 ;这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启动成功了。默认值为1 startsecs=1 ;程序启动使用的用户身份 user = root ;stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件) stdout_logfile=/data/PrometheusAlert/logs/PrometheusAlert.out ;把stderr重定向到stdout,默认 false redirect_stderr = true ;stdout日志文件大小,默认 50MB stdout_logfile_maxbytes = 20MB ;stdout日志文件备份数 stdout_logfile_backups = 10 EOF
supervisor启动PrometheusAlert服务
1 2 3 4 5 $ supervisorctl update && supervisorctl status grafana RUNNING pid 20601, uptime 1:56:44 loki RUNNING pid 18598, uptime 2:35:22 prometheus-alter RUNNING pid 26324, uptime 0:00:04 promtai RUNNING pid 19709, uptime 2:13:37
查看PrometheusAlert的日志,无报错即启动成功了,访问地址是http://主机ip:8080,账号密码是你配置文件里面配置的。
1 2 3 4 5 6 7 $ cat /data/PrometheusAlert/logs/PrometheusAlert.out 2022/12/01 13:15:40.808 [I] [proc.go:255] [main] 构建的Go版本: go1.17.5 2022/12/01 13:15:40.809 [I] [proc.go:255] [main] 应用当前版本: 'v4.8.2' 2022/12/01 13:15:40.809 [I] [proc.go:255] [main] 应用当前提交: eb8600a0597ab4f011c123083e2a457a11ea536e 2022/12/01 13:15:40.809 [I] [proc.go:255] [main] 应用构建时间: 2022-06-24T15:42:46+0800 2022/12/01 13:15:40.809 [I] [proc.go:255] [main] 应用构建用户: root@bogon 2022/12/01 13:15:40.865 [I] [asm_amd64.s:1581] http server Running on http://0.0.0.0:8080
登录平台测试下刚刚配置的飞书webhook是否正常。
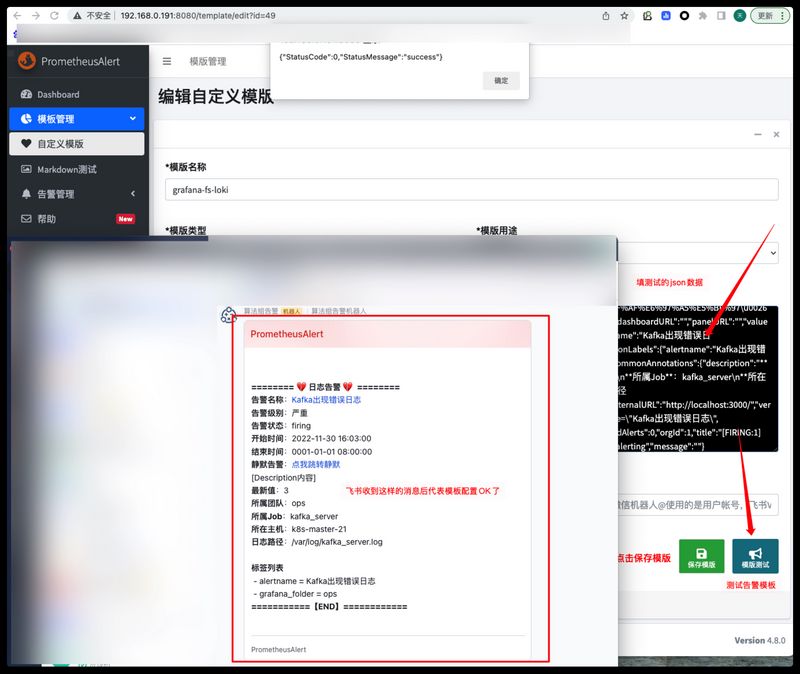
配置日志告警到飞书 配置prometheusAlert上Grafana日志告警模板 登录到PrometheusAlert平台,点击添加自定义模板
填写模板信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 {{if eq .state "ok" }} {{ range $k ,$v :=.alerts}}** ======== 💚 日志告警恢复 💚 ========** **告警名称**:[{{$v .labels.alertname}}]({{.generatorURL}}) **告警级别**:严重 **告警状态**:{{$v .status}} **开始时间**:{{GetCSTtime $v .startsAt}} **结束时间**:{{GetCSTtime $v .endsAt}} **当前**:**恢复正常** **===========【END】============** {{ end }} {{else }} {{ range $k ,$v :=.alerts}}** ======== 💔 日志告警 💔 ========** **告警名称**:[{{$v .labels.alertname}}]({{.generatorURL}}) **告警级别**:严重 **告警状态**:{{$v .status}} **开始时间**:{{GetCSTtime $v .startsAt}} **结束时间**:{{GetCSTtime $v .endsAt}} **静默告警**:[点我跳转静默]({{.silenceURL}}) [Description内容] {{$v .annotations.description}} **标签列表** {{ range $kk ,$vv :=$v .labels}} - {{$kk }} = {{$vv }} {{end}}**===========【END】============** {{ end }} {{end}}
测试下模版是否正常,使用下面的测试Json数据填写到消息协议JSON内容中,点击模板测试验证飞书是否收到格式化的告警消息。
1 { "receiver" : "grafana-promealert-mysql" , "status" : "firing" , "alerts" : [ { "status" : "firing" , "labels" : { "alertname" : "Kafka出现错误日志" , "grafana_folder" : "ops" } , "annotations" : { "description" : "**最新值**:3\n**所属团队**:ops\n**所属Job**:kafka_server\n**所在主机**:k8s-master-21\n**日志路径**:/var/log/kafka_server.log" } , "startsAt" : "2022-11-30T08:03:00Z" , "endsAt" : "0001-01-01T00:00:00Z" , "generatorURL" : "http://localhost:3000/alerting/grafana/Fmq-FVF4z/view" , "fingerprint" : "2b0c4c09a891c428" , "silenceURL" : "http://localhost:3000/alerting/silence/new?alertmanager=grafana\u0026matcher=alertname%3DKafka%E5%87%BA%E7%8E%B0%E9%94%99%E8%AF%AF%E6%97%A5%E5%BF%97\u0026matcher=grafana_folder%3Dops" , "dashboardURL" : "" , "panelURL" : "" , "valueString" : "" } ] , "groupLabels" : { "alertname" : "Kafka出现错误日志" , "grafana_folder" : "ops" } , "commonLabels" : { "alertname" : "Kafka出现错误日志" , "grafana_folder" : "ops" } , "commonAnnotations" : { "description" : "**最新值**:3\n**所属团队**:ops\n**所属Job**:kafka_server\n**所在主机**:k8s-master-21\n**日志路径**:/var/log/kafka_server.log" } , "externalURL" : "http://localhost:3000/" , "version" : "1" , "groupKey" : "{}:{alertname=\"Kafka出现错误日志\", grafana_folder=\"ops\"}" , "truncatedAlerts" : 0 , "orgId" : 1 , "title" : "[FIRING:1] Kafka出现错误日志 ops " , "state" : "alerting" , "message" : "" }
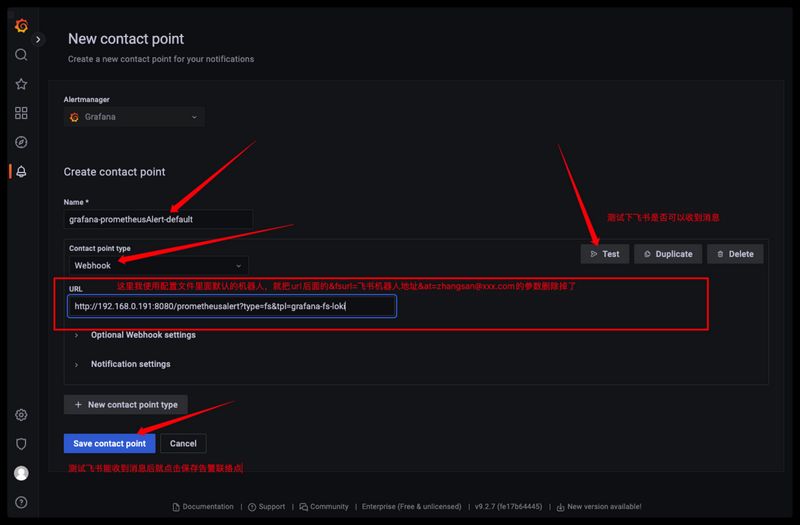
找到我们刚刚添加的自定义模板webhook通知地址,记录下来等下在Grafana里面添加告警联络点时要用到。
1 2 http://192.168.0.191:8080/prometheusalert?type =fs&tpl=grafana-fs-loki&fsurl=飞书机器人地址&at=zhangsan@xxx.com
配置Grafana上日志告警 登录Grafana平台进入到告警中心,新建一个webhook的联络点,webhook的地址就写刚刚复制的自定义模板路径。
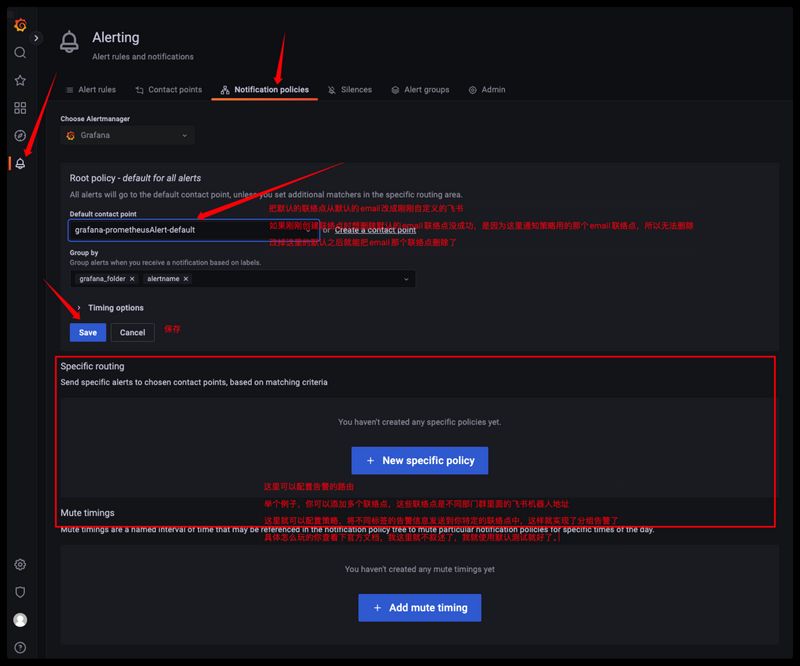
我们修改通知策略,把默认的通知渠道改成刚刚添加的飞书告警联络点
我们前面使用promtail收集了kafka的日志,现在配置一个kafka错误日志的告警规则示例。
需求就是:30分钟内当kafka服务的日志出现ERRO关键词 > 1次就发送告警信息。
注意:在点击New alert rule按钮来新建告警规则前,先在Search by data source中选择你的loki数据源。
添加告警规则的详情
第一步:设置查询指标和告警触发的条件
这里纠正一下:把第一步中查询A中的Sum这个参数删掉,不然无法获取告警数据的labels信息。告警发送过来时Description内容里面只有最新值,其他都是空的。
配置告警触发的抑制和告警的详细信息
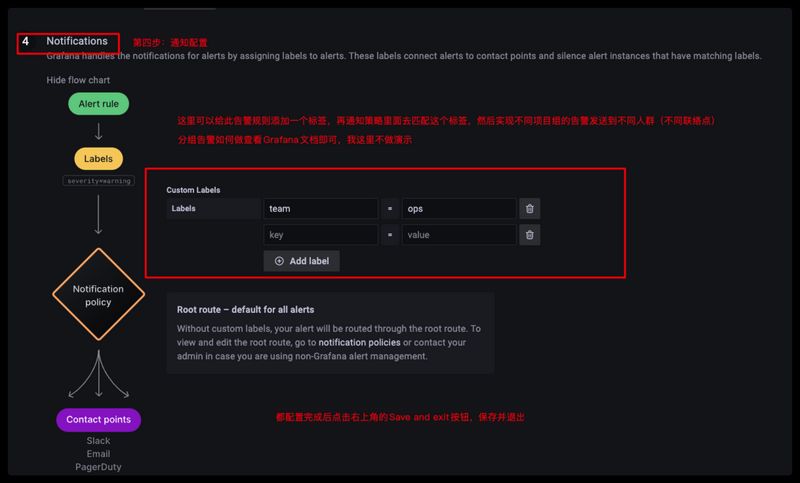
第四步:告警通知的配置,可以配置分组告警,我这里虽然给这个告警规则打了一个team=ops的标签,但是我是没有做分组告警的,默认都发送给告警策略里面配置的默认告警联络点中。
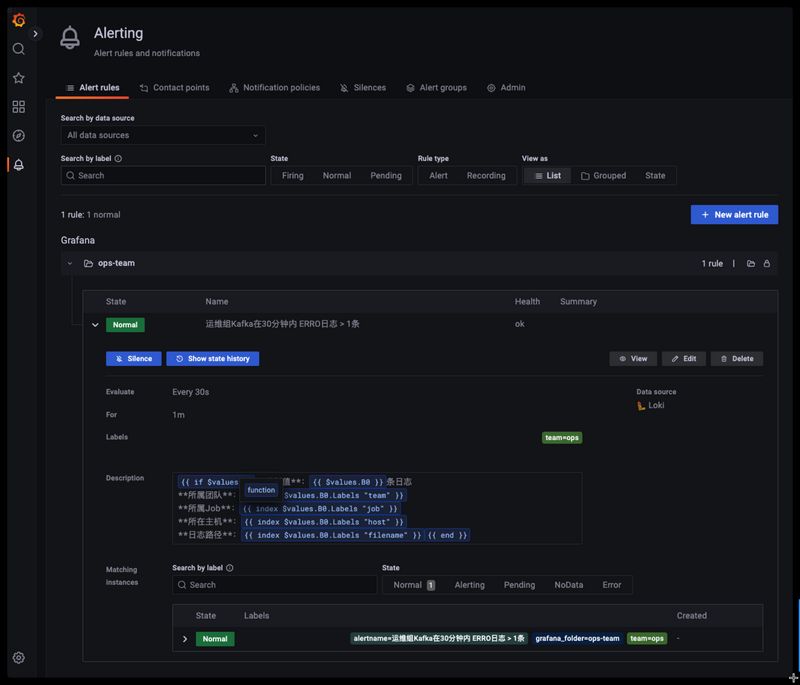
配置完成后就可以在告警规则列表里面看到刚刚创建的规则了
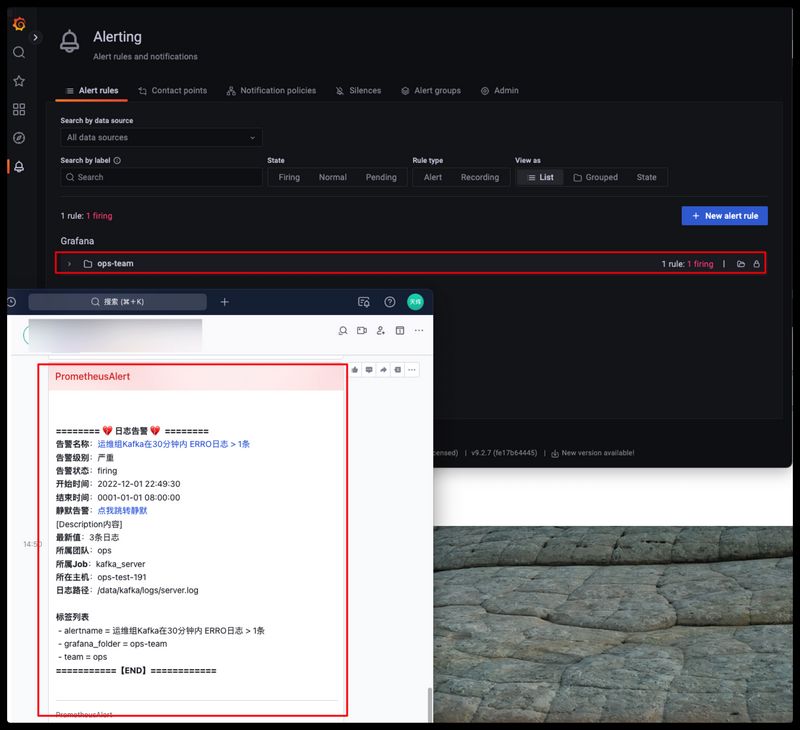
我们现在手动往kafka日志文件中写入两条包含ERRO关键词的日志,然后等一分钟后观察是否有告警发送到飞书这边来
1 2 3 $ echo '[2022-11-30 06:12:35,761] ERRO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)' >> /data/kafka/logs/server.log $ echo '[2022-11-30 06:12:35,761] ERRO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)' >> /data/kafka/logs/server.log
等待30s钟后,刚刚创建的告警规则就会从ok变成pending,然后持续一分钟后从pending变成firing,飞书就能收到日志的告警信息了