## 关闭selinux /]$ setenforce 0 /]$ vim /etc/sysconfig/selinux SELINUX=disabled
2.3 关闭THP
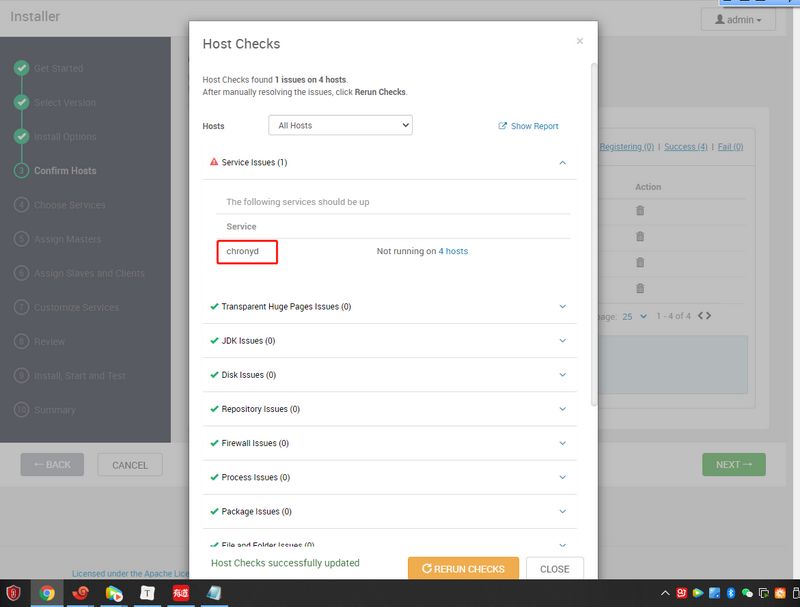
如果不关闭THP,Hadoop的系统cpu使用率很高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## 临时关闭 /]$ echo never > /sys/kernel/mm/transparent_hugepage/enabled /]$ echo never > /sys/kernel/mm/transparent_hugepage/defrag
## 开机自启动关闭 /]$ cat >> /etc/rc.local << EOF if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi EOF
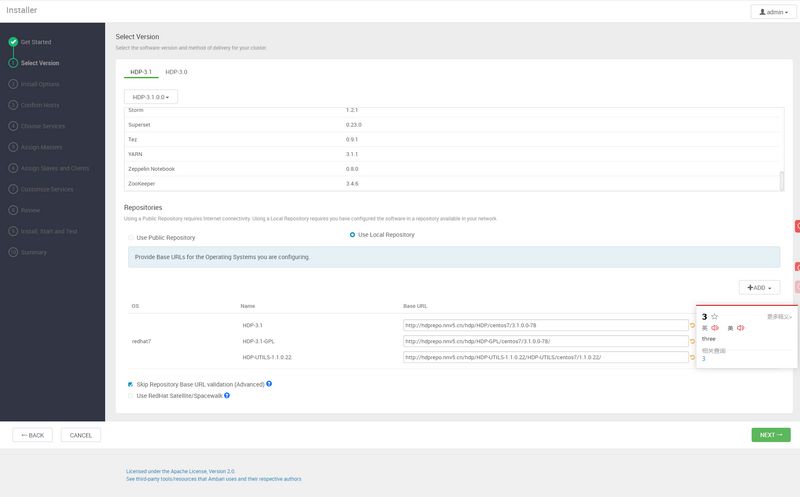
/]$ wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo /]$ yum install -y nginx /]$ vim /etc/nginx/nginx.conf server { listen 80; server_name hdprepo.nnv5.cn; root /data/wwwroot/; include /etc/nginx/default.d/*.conf; index index.html index.htm index.php; autoindex on; autoindex_exact_size on; autoindex_localtime on; }
/]$ mkdir -p /data/wwwroot/{hdp/HDP-UTILS-1.1.0.22,ambari} /]$ nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful
# 加载ambari-server的mysql表结构 /]$ mysql -uroot -p sql> source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
# 配置ambari-server /]$ ambari-server setup Using python /usr/bin/python Setup ambari-server Checking SELinux... SELinux status is 'disabled' Customize user account for ambari-server daemon [y/n] (n)? y # 以后台守护进程启动ambari-server Enter user account for ambari-server daemon (root):root # 启动的用户 Adjusting ambari-server permissions and ownership... Checking firewall status... Checking JDK... Do you want to change Oracle JDK [y/n] (n)? y # 是否更改JDK [1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8 [2] Custom JDK ============================================================================== Enter choice (1): 2 # 使用自定义JDK WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts. WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts. Path to JAVA_HOME: /usr/local/jdk1.8.0_211 # JDK目录 Validating JDK on Ambari Server...done. Checking GPL software agreement... Completing setup... Configuring database... Enter advanced database configuration [y/n] (n)? Y # 是否配置数据库 Configuring database... ============================================================================== Choose one of the following options: [1] - PostgreSQL (Embedded) [2] - Oracle [3] - MySQL / MariaDB [4] - PostgreSQL [5] - Microsoft SQL Server (Tech Preview) [6] - SQL Anywhere [7] - BDB ============================================================================== Enter choice (3): 3 ####如果主机字符集编码未设置正确,可能会启动报错,具体可以查看日志/var/log/ambari-server/ambari-server.log Hostname (localhost): hdp01.nnv5.cn Port (3306): # 默认3306端口 Database name (ambari): # ambari-server的数据库名称 Username (ambari): # ambari-server的用户名 Enter Database Password (bigdata): # 数据库的密码 Re-enter password: Configuring ambari database... Should ambari use existing default jdbc /usr/share/java/mysql-connector-java.jar [y/n] (y)? y # 是否使用默认的jdbc驱动 Configuring remote database connection properties... WARNING: Before starting Ambari Server, you must run the following DDL directly from the database shell to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql # 此处需注意,启动ambari之前需要执行此句 Proceed with configuring remote database connection properties [y/n] (y)? y Extracting system views... ambari-admin-2.7.3.0.139.jar .... Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json, updating stacks repoinfos with it... Adjusting ambari-server permissions and ownership... Ambari Server 'setup' completed successfully. # 安装成功
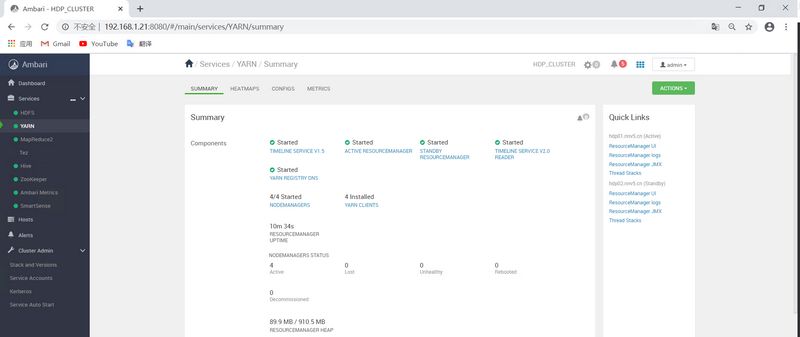
/]$ ambari-server start Using python /usr/bin/python Starting ambari-server Ambari Server running with administrator privileges. Organizing resource files at /var/lib/ambari-server/resources... Ambari database consistency check started... Server PID at: /var/run/ambari-server/ambari-server.pid Server out at: /var/log/ambari-server/ambari-server.out Server log at: /var/log/ambari-server/ambari-server.log Waiting for server start...................... Server started listening on 8080 # 启动成功,浏览器访问http://ip:8080
DB configs consistency check: no errors and warnings were found. Ambari Server 'start' completed successfully.
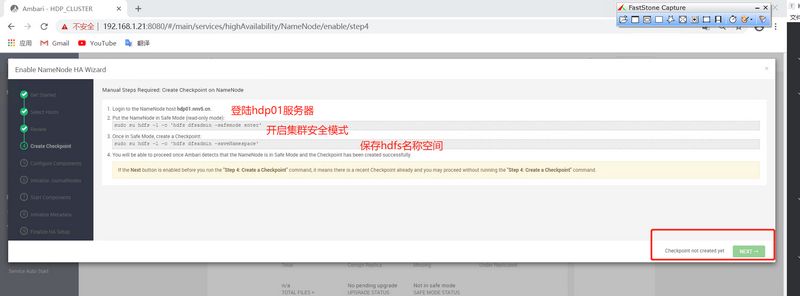
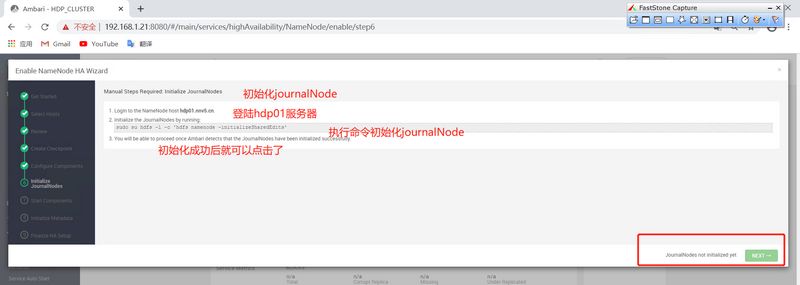
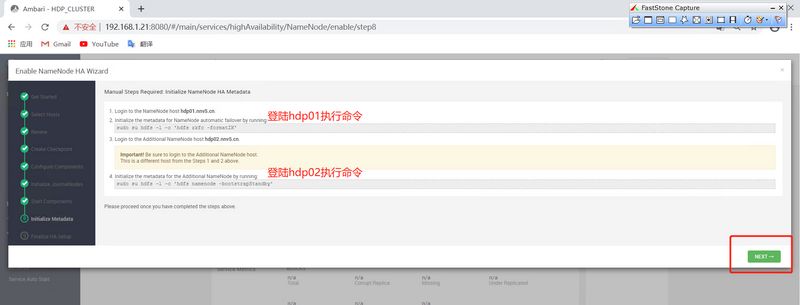
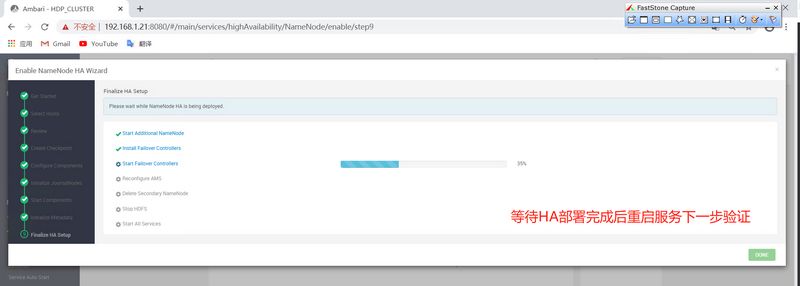
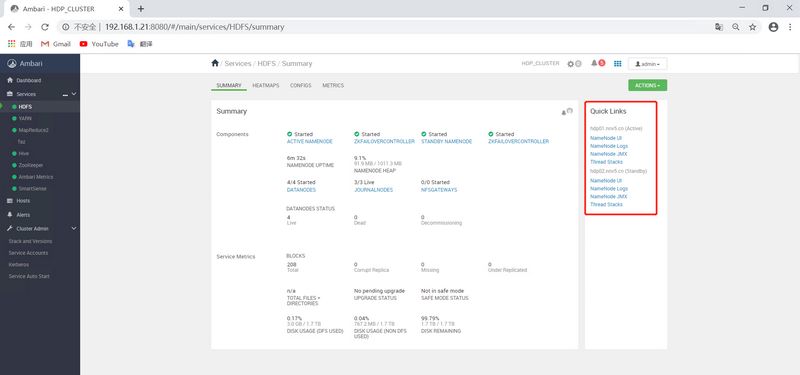
]# sudo su hdfs -l -c 'hdfs namenode -initializeSharedEdits' 20/06/09 15:13:53 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hdp01.nnv5.cn/192.168.1.21 STARTUP_MSG: args = [-initializeSharedEdits] STARTUP_MSG: version = 3.1.1.3.1.0.0-78
20/06/09 15:13:56 INFO client.QuorumJournalManager: Successfully started new epoch 1 20/06/09 15:13:56 INFO namenode.RedundantEditLogInputStream: Fast-forwarding stream '/data/hadoop/hdfs/namenode/current/edits_0000000000000004426-0000000000000004426' to transaction ID 4426 20/06/09 15:13:56 INFO namenode.FSEditLog: Started a new log segment at txid 4426 20/06/09 15:13:56 INFO namenode.FSEditLog: Starting log segment at 4426 20/06/09 15:13:56 INFO namenode.FSEditLog: Ending log segment 4426, 4426 20/06/09 15:13:56 INFO namenode.FSEditLog: logSyncAll toSyncToTxId=4426 lastSyncedTxid=4426 mostRecentTxid=4426 20/06/09 15:13:56 INFO namenode.FSEditLog: Done logSyncAll lastWrittenTxId=4426 lastSyncedTxid=4426 mostRecentTxid=4426 20/06/09 15:13:56 INFO namenode.FSEditLog: Number of transactions: 1 Total time for transactions(ms): 0 Number of transactions batched in Syncs: 0 Number of syncs: 1 SyncTimes(ms): 13 20/06/09 15:13:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hdp01.nnv5.cn/192.168.1.21 ************************************************************/
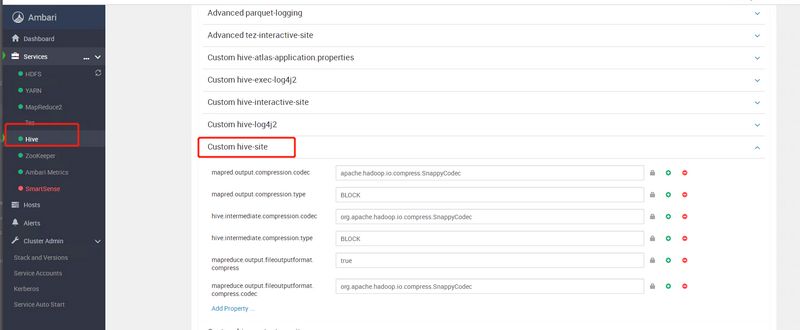
## Map/Reduce 输出压缩 set hive.exec.compress.output=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; set mapred.output.compression.type=BLOCK;
## 任务中间压缩 set hive.exec.compress.intermediate=true; set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; set hive.intermediate.compression.type=BLOCK;
## job输出文件压缩 set mapreduce.output.fileoutputformat.compress=true; set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec; set mapreduce.output.fileoutputformat.compress.type=BLOCK;